
How to debug large, distributed systems: Antithesis
A brief history of debugging, why debugging large systems is different, and how the “multiverse debugger” built by Antithesis attempts to take on this challenging problem space


Below is a deepdive on Antithesis from November 2024. The article was originally for paid subscribers only, made free in May 2026.
Fast forward to 2026, and a lot has changed with Antithesis: you can now deploy the service or software you want to test (the “system under test,” or SUT) into a hostile environment whose sole purpose is to break it for you. All of this is deterministic and fully replayable, so you can easily reproduce any and all bugs found.
This environment does some seriously cool things. For example, it compresses 24 hours of test runs into 30 minutes:
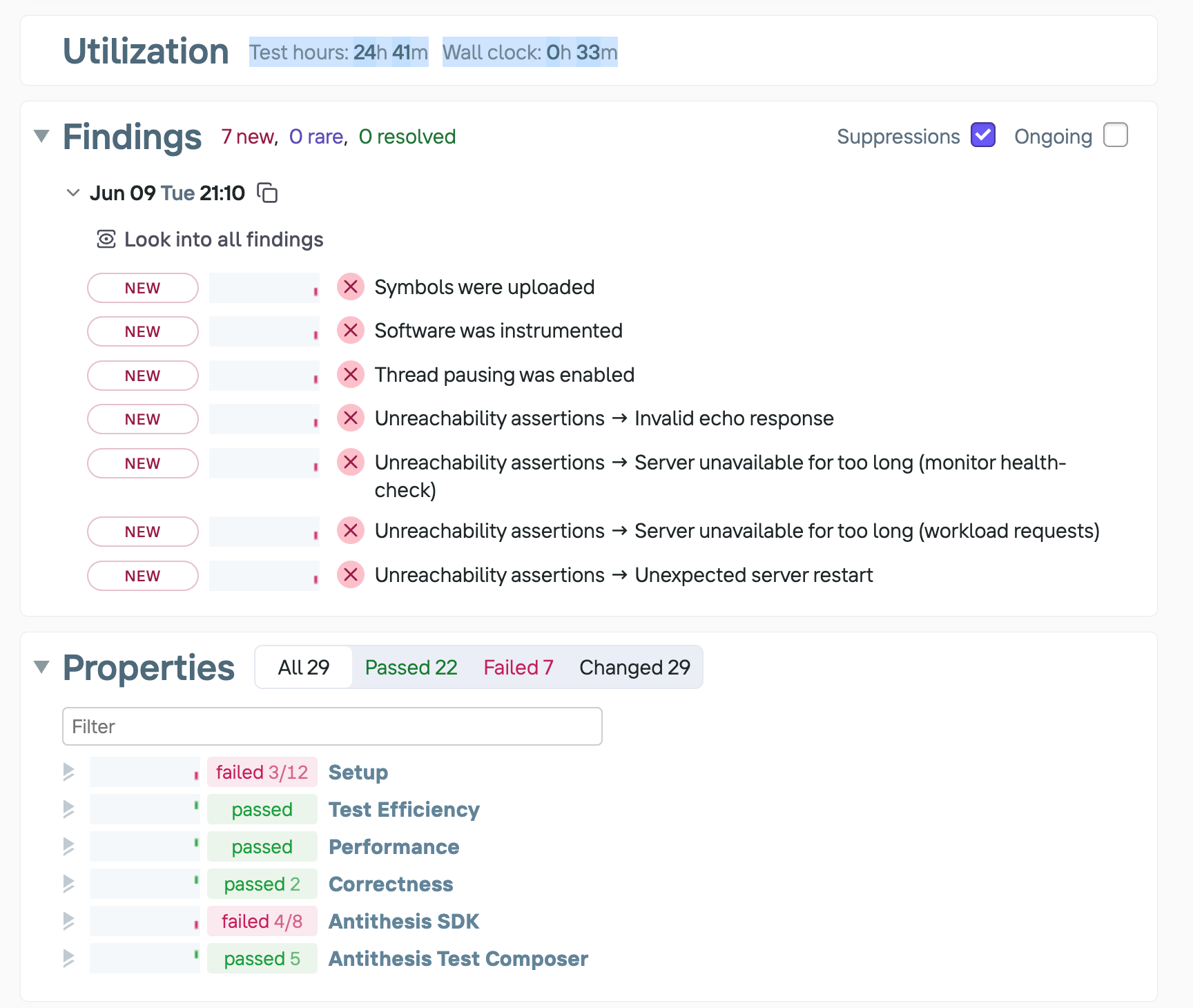
This environment is kind of like an extreme version of chaos engineering. There are both random inputs thrown at the system (similar to fuzzing), as well as deliberate fault injection.
Antithesis is the presenting sponsor of The Pragmatic Engineer Podcast for the Summer 2026 season. Learn more about how Antithesis works: I appreciate just how ambitious their team is.
Debugging is one of those things all engineers do, but little has changed in how we debug for decades. For example, debugging by printing to the console output or by logging is still pretty common, even though there’s decent debuggers that can be used across IDEs.
Believe it or not, some debugging tools today are actually less advanced than in the old days. Steve Yegge, head of engineering at Sourcegraph – said last year:
“I saw the best debugger I’ve ever used at GeoWorks, in 1990. To this day, I’ve yet to see a debugger do what theirs did back then: path choice on the fly, undo on the spot, or step an instruction backwards.”
This stagnant rate of progress makes it very interesting that there’s a small engineering team working today on building a much better debugging tool, which specifically focuses on debugging large and distributed systems. It’s called Antithesis, and is the focus of this article.
Today, we cover:
Brief history of debugging
Antithesis’ “multiverse debugger”
Q&A with Antithesis co-founder, Will Wilson
Tech stack
Engineering team and culture
Advanced testing tools for better bug management
Better bug management with advanced testing tools
Tradeoffs of complexity
1. Brief history of debugging
Debugging and software development have gone hand in hand since the earliest days of computing. But why do we call it ‘debugging’? The etymology is a bit obscure, but it could include a real-life insect.
First “debugged” computer
In 1947, a team of scientists at Harvard University including computer science pioneer, Grace Hopper, found a moth trapped in a relay of the Mark II mainframe computer which was causing it to malfunction. The fault was documented, and the moth itself was added to a hand-written record, reading: “...first actual case of bug being found.”

Faults were called “bugs” before this incident, but the serendipitous episode may have helped cement the term “debugging” in the lexicon. Several computer science papers from the 1950s mention “debugging” in passing, which suggests the word was in use and its meaning was common knowledge among professionals. It also appears in the 1963 manual of the first time-sharing operating system, the Compatible Time-Sharing System (CTSS.)
Evolution of debugging tools
Programmers have always built tools to make their lives easier, and debuggers are a case in point. Here’s how the toolset evolved from the 1960s.
1960s: punch card era. The earliest debugging tools:
Typewriter debugging: DEC Debugging Tape (DDT): a debugger program that worked on a typewriter! It allowed the modifying of a program or its data on the mainframe, while it was running. (DEC stands for “Digital Equipment Corporation”, which was a major computer hardware company of the time.) This was an era when the typewriter served as the command line interface. See the full manual for commands.
Online Debugging Tool (ODT): a family of debugger programs that allowed the accessing of memory using octal addresses while software ran. Also produced by the Digital Equipment Corporation.
1970s: (symbolic) debuggers. New, powerful programming languages like C, FORTRAN and COBOL were developed in the ‘70s, which allowed fetching of symbol maps that showed the memory addresses of variables. Symbol maps were used for more efficient debugging, as they made it unnecessary to manually track memory addresses. The tools in use today are symbolic debuggers.
Late 1970s: breakpoints. With the ability to inspect the memory of a running program and to get a memory dump, the next debugging task is to halt program execution on a given condition, like a variable reaching a certain value. Breakpoints allow for precisely that.
The core functionality of halting program execution emerged in the 1940s, with involved approaches like removing cables, deliberately causing program crashes, and via hardware switches. Over time, the utility and usability of breakpoints evolved, and by the end of the ‘70s, they were in symbolic debuggers in ways recognisable today. More advanced tools added the option of allowing a program to advance one step forward (step forward) and the more complex functionality of going back (step back.)
Mid-1980s: “modern debugging.” From the 1980s, the software development experience continued to evolve with better terminals, more interactivity, and ever-tighter feedback loops. Debugging improvements followed a similar pattern. For example, in 1983 Turbo Pascal introduced its IDE with built-in debugging capabilities – which might have been the first “mainstream” IDE with debugging enabled.
Graphic debugging tools with visual breakpoints and output were innovations of this time. Remote debugging – debugging programs running over networks – became possible with the spread of the internet.
Today’s modern debugging tools have modern features, such as:
Time-travel debugging. Also known as “reverse debugging”, this is most common within functional programming and in deterministic environments. It allows recreating issues, and to “step backwards” to figure out root causes. Today’s deep dive is on one such tool, Antithesis.
Record and replay debugging. The application state is recorded in each step of the process and can be replayed. Recordings tend to include memory state, memory interactions, inputs, and system resource status markers, among others. ReDevBug does this.
Automatic debugging. Tools that can automatically locate and sometimes fix bugs in code. These debuggers are usually ML or AI-driven.
AI-assisted debugging. The latest wave of debugging uses GenAI to predict and locate bugs in a more efficient manner. It’s early days, but we can expect more solutions like this.
2. Antithesis’s ‘multiverse debugger’
Antithesis was founded in 2018 with the vision of a better way to test systems, and it has raised an impressive $47M (!!) in seed funding. The business model is usage-based pricing, based on the number of CPUs used for testing activities; a good analogy is Amazon renting out its EC2 servers. Today, Antithesis sells cores on an annually-reserved basis, with a minimum for getting started with, and hopes to offer more flexibility in the future, I’m told.
Time-travel debugging tools are usually limited to functional languages where state management is simple, or to deterministic environments; like in well-defined sandboxes. For most real-world programs, no time travel option is available for debugging, so when a backend service crashes non-deterministically, there’s no good way to turn back time and investigate it; the best option is usually to add more logging to help explain future crashes.
Building a time machine
The Antithesis team spent several years building a system that acts like a time machine. It wraps your current system, and lets you rewind your steps. Within the “wrapper”, to rewind the state of the system to 5 seconds earlier, you type:
branch = branch.end.rewind(5).branch
Files deleted within the last five seconds come back, including if deleted permanently without being put in deleted file storage. Any changes made in files since are also undone.
Creating the time machine means creating a deterministic simulation, which can progress from its starting point to the future, arbitrarily. It can go back in time, too, which raises interesting possibilities. For example, if your server crashed: wouldn’t it be great to “rewind” time and attach a debugger? In a simulated system, you can do this: simulate the system to the point where the process will crash, then add a debugger or export a memory dump. Similarly, if a user reports that their session was slow: it’s now possible to go “back in time” by recreating their session, and attaching a debugger.
Having a deterministic simulator creates previously hard-to-achieve scenarios, such as:
Jump into the future; for example, by fast-forwarding a system 10 hours in the future, to inspect how memory usage and CPU usage will trend at that time. This is not a prediction, but it allows actually inspecting the future state of the system!
Generate more logs to work with. When a suspicious event is identified in the present, you can go back in time and add more logging to where this event may have originated from. You could also enable detailed logging across the system for a few minutes or seconds before an event occurs.
Change the past. Go back to before a crash happened, and change the code executing.
What Antithesis does
Antithesis is not only a time-traveling debugger, though. A good way to describe it is as “Deterministic Simulation Testing (DST) as a service.”
Deterministic Simulation Testing (DST) is a technique of building a simulation in which software can run in a single thread, and where you’re in control of all variables like time, randomness, etc., in order to achieve determinism during testing.

DST is a combination of:
Fuzzing: also referred to as “fuzz testing,” this is automated testing that inputs invalid, unexpected, or random inputs to a program.
Assertions: making logical statements that should always be true or false, and breaking the program when an assertion fails; e.g.; asserting that an integer variable’s value is always greater than zero, so the program breaks when this condition fails.
Shotgun debugging: making random changes to software and seeing if it fixes the bug.
Time travel debugging: the ability to “step backward and forward in time,” within the state of the program.
Doing Deterministic Simulation Testing is really hard for any system because you have to build everything from scratch. No existing frameworks and libraries without support for all time-traveling, debugging, fuzzing, etc, can be used. One of the first “proper” usages of DST was within the distributed database, FoundationDB, one of whose creators is Antithesis cofounder, Will Wilson.
Because implementing DST is so difficult, Antithesis made the computer/hypervisor deterministic, instead. This means anything that runs on this Antithesis computer/hypervisor can be tested with DST, without doing everything yourself.
And thanks to running a fully deterministic environment, Antithesis can manipulate it into weird states on purpose, which allows developers to inspect weird states and bugs to find out their causes. Read more on how Antithesis works.
3. Q&A with Antithesis co-founder, Will Wilson
The company’s CEO took some questions from us, and in this section the questions are italicized, with Will’s responses in normal text.
How debugging large systems is different
The Antithesis tool was built to debug large and complex systems, but how are these systems different from common ones like single services, apps, and single-threaded websites?
‘A few things make large systems different:
Bizarre failures are a certainty. If your software runs on one computer, things like bitflips in memory, or corruption on disk are exceptionally uncommon. If your software runs on a cluster with tens of thousands of machines, you’d better have a plan for it.
Expectations are usually higher. If your software runs on one computer, and it crashes, there’s not a lot your software can do to improve the situation, except not losing any durable state. But if your software runs on a large cluster, people probably expect it to function if one or two machines die.
Concurrency plays a bigger role. You can get in trouble with multi-threaded systems on a single machine, but with many machines and unreliable/noisy networks between them, it gets so much worse.
Timestamps are meaningless. Unless you’re Google and have atomic clocks in your datacenters, you need to assume that clocks on different machines are not perfectly synchronized, which can make reading logs very confusing. You may literally not know whether an event started on system A or system B!
Large systems probably don’t “fit inside the head” of any person, which can make reasoning through the state machine the old fashioned way, much harder. Also, the sheer length of time and numbers of people it takes to build these systems, means there are many opportunities to lose institutional knowledge, or memories to fade.’
‘All of the above make testing and debugging large systems much harder, especially the first three points. Many failure modes of large-scale systems are “external” or environmental, and to do with hardware faults, network messages getting delayed, or weird pauses on a thread. These are harder to reason about in advance, and they’re monumentally harder to test for and debug, as they may depend on highly specific conditions or timings that are almost impossible to reproduce on demand.
‘The paradox of distributed systems is that a one-in-a-million bug can be a huge urgent problem because you’re processing millions of requests all the time, so the bug will occur frequently. But, it’s still a one-in-a-million bug, so a test probably won’t reproduce it!’
How Antithesis is used
Where does Antithesis fit into customers’ software delivery and process timelines?
‘We see customers using Antithesis in very different ways. There are teams who run short tests on almost every PR, or who run long tests overnight or weekends, and some teams only pull it out when trying to track down a really crazy bug.
‘We don’t tell our customers they should eliminate any of their existing tests because it’s probably inexpensive to keep them, and we don’t want to be the cause of any outage or emergency. That said, many customers stop investing as much in non-Antithesis tests, and instead try to find ways to use our platform for as much testing as possible.
‘Some customers have come up with really creative ways to use our platform. For example, who said this tool can only be used for hunting bugs? It’s a general platform for looking for any behavior in software systems. For example it can help answer questions like:
“Can function A ever run before function B? Or does this function ever get called with a negative parameter?”
‘Most of what Antithesis “replaces” is human effort of the really annoying, unpleasant kind, like adding logging, then waiting for it to happen again in production. Or designing weird, ad-hoc fault injection systems in end-to-end tests. Or writing a script to run an integration test dozens of times to chase down an intermittent problem that only occurs once every ten runs. Basically, the stuff no programmer enjoys doing.’
4. Tech stack
What is the tech stack behind Antithesis? DST is hard to do with existing libraries, so which frameworks you might use instead of writing a bespoke one?
‘We have a pretty bad case of “not-invented here” syndrome. Basically, compared to most companies, we see a larger cost to adopting lots of third-party dependencies. So we bias towards building tools in house that do exactly what we need, which means our tech stack is very “home-grown”.
‘Languages we use often:
C and C++: languages with low-level memory manipulation, helpful for high-performance scenarios and necessary for kernel-mode code
Rust: a modern programming language emphasizing performance, type safety and concurrency
Typescript: a language adding static typing for JavaScript. Popular across backend and frontend domains
Nix: a language to create derivations (precise descriptions of how contents of existing files are used to derive new files)
‘Our major dependencies:
Nix/NixOS: a tool for package management and system configuration
BigQuery: a managed serverless data warehouse product by Google
Hypervisor: we use a fork/rewrite of the FreeBSD kernel hypervisor, bhyve.
‘Our homegrown stack is surprisingly large!
Hypervisor: custom-built for our needs; more details here.
A fully-reactive browser-based Javascript notebook. It has sophisticated dependency tracking. We currently use it to deliver the multiverse debugging experience
Fuzzer: optimized for exploring the state space of interactive programs (read more about fuzzing)
Fault injector: a testing tool to deliberately introduce failures, errors or problematic conditions
Binary instrumentation for customer software: inserting additional code (instrumentation code) into a customer’s compiled program to analyze its behavior during runtime.
Customizable Linux environment: what customers’ software run in
Build system: based on Nix, which glues our systems together
Infrastructure and security mechanisms, built to ensure we run a trusted computing base
‘Our homegrown stack is huge! One of the coolest things about working at Antithesis as an engineer is that if there’s any computer science topic you’re interested in, there’s a good chance we do it, at least a little.
Building a database
‘We started using BigQuery very early because the pricing model is unbeatable for a tiny startup with bursty workloads. But the data model did not make much sense for us.
‘Our use case is to analyze ordered streams of events: logs, code coverage events, etc. But because we have a deterministic multiverse which can fork, the stream of events form a tree structure rather than a single linear history! But BigQuery is not well set up to handle trees of events, and neither is any other SQL database.
‘We managed to putter along for a while with crazy hacks. For instance, we built a new data structure called a "skip tree", inspired by the skip list which we implemented in SQL. This data type greatly improved the asymptotic performance of our queries (the performance characteristics at scale). However, we eventually got to the point of regularly crashing BigQuery's planner; at which point we knew we had to move to something else.
‘We evaluated Snowflake, and its Recursive CTE feature, and also evaluated a large number of other SQL and NoSQL databases, but nothing fundamentally fixed the problem.
‘We were hesitant to build our own database for ages, until a company hackathon where a team tried writing a proof-of-concept analytic database for folding Javascript functions up and down petabyte-scale trees, thrown together in a week using Amazon S3 and Lambda. It actually worked!
‘We're cautious, and a lot of people on our team have built databases before. We know that the hardest part of building a database is not getting started, but towards the end of the project with testing and operationalizing. But we do have this really great technology for testing distributed systems!
‘We decided to write a custom database for our needs, 100% tested with Antithesis. We would have no other test plan except for running it with Antithesis! We are now nearing the end of the project, and so far, it’s going well!
‘If we succeed, it would solve a huge number of production issues with BigQuery, and enable us to launch some amazing new features. Plus, this project gives us the ultimate empathy with customers.
5. Engineering team and culture
Tell us about the engineering team’s values and practices.
‘Most of our team is in Virginia just outside Washington, DC. We also have a small office in the UK. Virginia is an unusual place for a deep tech startup, but we love it. There’s an incredible amount of programming talent in the area, mostly at government agencies. At the same time, there are barely any startups! People tend to stay in jobs much longer than in the Bay Area, which helps build a strong engineering culture and institutional continuity.
‘We’re big on the long-term view, which applies to colleagues and relationships, too. For example, we sometimes hire junior people, or from non-traditional backgrounds. We do this when we see a spark, and think there’s a chance that in a year or two they could be great. We’re making big investments in people, so we hope they stick around for a long time. Generally, they do!
‘In the history of the company, we’ve only had a few engineers voluntarily depart. In fact, a large part of our team worked with us at our previous startups, FoundationDB, which Apple acquired in 2015, and Visual Sciences, now part of Adobe.
‘Some people have literally been working together for over 20 years at this point!
‘We try very hard to not let people get pigeonholed by over-specializing in one area. There’s a pathology in some companies where whatever’s “on fire” on the day you join, that’s what you become expert in, and what you spend your time there doing.
‘We try hard to rotate people through different parts of our very large stack, and give them exposure to all kinds of stuff, like:
Low-level hypervisor code
Frontend code
Machine learning systems
Security critical code
Large-scale cloud infrastructure
… and more
‘Of course, there’s room to specialize. Our goal is to ensure every engineer has at least some familiarity with areas outside of their main domain because it makes communication easier.
‘We’re fanatically in-person, working from the office 5 days a week. This is perhaps the most unusual thing about us; we’ve been in the office full time since Covid-19 vaccines became available.
We believe the biggest challenges of operating large engineering teams are communication complexity, and knowledge transfer. Remote working makes extremely difficult tasks way harder, and we’re intensely collaborative; we often spend more time debating how something ought to work than on implementing it!
‘We put collaboration and being collaborative as a very high priority. We recognize a big part of somebody’s value is their effect on others. We celebrate and reward employees for mentoring others, helping coworkers solve problems, and doing things that aren’t strictly their job. We have zero tolerance for assholes, and fire them immediately.
‘Our engineers work on desktops, not laptops. They are literally unable to take their work home with them. At the same time, we work pretty hard at work!
6. Advanced testing tools for better bug management
Your team recently gave a talk about using Antithesis on Antithesis; what are some top takeaways from testing and debugging a system like it?
‘It’s amusingly difficult to use Antithesis to test itself. Still, we test Antithesis on itself because it means we’re using our own product every day. Following this practice also means that we find lots of bugs early and fix them early, which hugely increases our productivity.
‘A big challenge was to test Antithesis before it was actually able to test itself. ‘We did this early-stage testing by building several custom fuzzers, purpose-built autonomous testing systems for various components.
‘We are now in the process of decommissioning these custom testing tools, and aim to replace them with our own product. This is an interesting challenge, and a frequent source of new feature requests for Antithesis.
‘Bugs which “evolve” to get around your testing are always hard to deal with. One of the most important ways we fight them is by recording every bug we hit in production that’s not captured by tests. We try to figure out why not, and what could make our testing more powerful, so it doesn’t recur. We don’t think about this in terms of adding a test, but rather in how to improve autonomous tests, so they catch an entire class or category of issues that previously slipped through the net. We have some material in our documentation about using production bugs to improve tests.’
7. Better bug management with advanced testing tools
Gergely here, we recently published a deep dive on bug management, and how to find bugs. How does a solution like Antithesis help to find and prioritize bugs?
‘The single most important fact about bugs from which all our beliefs derive, is that they’re vastly cheaper and easier to fix if caught right after they’re introduced. Consider two scenarios:
‘Scenario #1: catching a bug immediately. You introduce a subtle, dangerous error in your code; but luckily your compiler, pre-commit unit test, or syntax highlighter, catches it.
‘The cost to fix this bug is approximately zero engineer hours! You literally just have to press Ctrl+Z.
‘Scenario #2: catching a bug much later. The same bug as in scenario 1 slips past all tests and makes it into the main branch, isn’t caught, gets deployed to a staging cluster, still isn’t caught, then it makes it into a release, again isn’t caught, then six months go by and it still isn’t caught. You quit your job, and somebody else is maintaining the code, who then moves to another team. Then a third person is maintaining it who never met you. And then a customer hits the bug in the middle of the night, and files a totally unhelpful bug report.
‘The cost to fix this bug is weeks or months of effort; orders of magnitude different from scenario #1.’
Catch bugs early
‘The best bug management approach catches bugs quickly. Whatever bug management process you choose, the goal is to have bugs mostly fall into scenario #1, not scenario #2. In fact, if literally all your bugs are scenario 1 (detected early), then they’re trivial to fix!
‘If you manage to do this, you can exist in a blessed zero-bug state and be incredibly productive. This may sound unrealistic, but it’s pretty much what we had at FoundationDB, and we know other teams achieved it, too.
‘The most important way that a tool Antithesis can help with bug management is to move bugs from scenario #2 to scenario #1. In fact, we see this as almost the whole point of our product!
‘Bugs can shield other bugs, which is another reason why fixing them early is such a smart strategy. You might think many bugs simply don’t “matter.” However, I’ve seen so many times that smaller bugs hide other, more impactful ones. If your system sometimes mysteriously crashes, it may be difficult to tell there’s another cause. This moves bugs from scenario #1 to scenario #2, which is the opposite of what we want, and very bad for productivity!
Fanatical bug prioritization
‘Let’s be honest, readers probably work on teams with a giant backlog of bugs. Many large teams are like this, and people might ask if a way exists to get the productivity benefits of scenario #1; all bugs detected and fixed quickly”
‘Be absolutely fanatical about prioritizing new bugs over old ones. This is the approach we have seen work best, even for larger teams. This means that anytime you find a bug in scenario #1 (or close to it), fix it as fast as possible. It’s okay to let the older ones fester. Working on fixing fresh bugs is usually much more efficient in terms of bugs-fixed-per-hour.
‘Antithesis supports this workflow by making it easy to figure out if a bug already exists. Basically, the tool can help implement this kind of policy:
“I already know about that bug. If it breaks in exactly this way, I don’t want to hear about it again. Only tell me about new ones!”
‘Our product efforts in this area are improving, and this is the form of categorization we really want to assist with.
Categorizing by severity is a double-edged sword
‘One question we often get is “what about fixing severe bugs first; surely the most impactful bugs should be addressed before new ones?
‘Our team is actually pretty much against trying to categorize bugs by severity. In our experience, giant, company-stopping global outages are often caused by “mild” bugs triggering some unexpected interaction.
‘This is a topic on which it’s safe to disagree. We have plenty of customers that do treat severity as an important signal. There’s nothing stopping users from using information from our system to do their own severity classification. Do what works for you!’
8. Tradeoffs of complexity
In this section, we share this publication’s independent opinion of tools like Antithesis.
Every tool has its own tradeoffs; there are cases for which it’s a great fit, and times when it offers more nuance than direct help. Antithesis is no exception.
Phil Eaton is a staff engineer working on Postgres products at EnterpriseDB. He shared his thoughts on the tradeoffs of Deterministic Simulation Testing (DST). Given Antithesis is a “DST as a service” these considerations apply to it. Phil’s take:
Users must understand the tool. Even with a tool like Antithesis, you need to put in the work to thoroughly understand your systems and how they should work, in order to instrument them properly and actually explore the whole application. The user of applications like Antithesis must do additional work to make the tool useful.
Mock third parties. If you need to mock a lot of third-party behavior with a tool like Antithesis to make it work, this might limit the value you get out of it.
Frequent code changes reduce value. If you’re working in an environment where you’re constantly building new things and changing how things work, these tools might not be that helpful.
Our thoughts:
Forget about “buy tool = problem solved.” A CTO cannot simply purchase a tool like Antithesis and then expect bugs to be magically fixed. After introducing such a tool, priorities need to change. Also, the engineering culture might need to adapt to prioritize exploring and fixing bugs, in order for quality improvements to emerge.
Prototyping and experimentation are poor fits. When a product is not yet mature, there seems relatively little value in running simulations.
How important is resiliency? For software that doesn’t need to be highly resilient, a tool like Antithesis might be overkill. The same goes for companies not valuing bug-free software, or high-quality production values. But for products that pride themselves on almost-zero bugs, this tool makes a lot of sense. One company which cares about quality – and uses Antithesis – is MongoDB. In a guest post, they write: “MongoDB is heavily invested into improving productivity through excellent testing.”
Pricing and ROI matter. Do the math on how much it would cost to run a system like Antithesis, versus how much it saves by finding and fixing bugs early. For example, instrumentation SaaS, Polar Signals, used Antithesis in preview and concluded the pricing didn’t work at the time. They currently use an in-house DST solution.
Takeaways
Thank you to Will and the Antithesis team for sharing details on how they work and operate. To keep up with Antithesis, you can follow their engineering blog, and follow Will on LinkedIn. Here’s what stands to me out from our conversation:
Startups do not need to be “conventional.” Antithesis does so many things that are the polar opposite to conventional “best practices”, such as:
Built most of the tech stack from the ground up, instead of reusing existing software and code
Use desktops, not laptops, and work five days a week in the office.
Building their own database engine from scratch, despite the conventional wisdom against it
Out of context, it sounds like a bad idea! But it makes sense when you understand the specific context of Antithesis.
Also, it’s good to question best practices. Take how Antithesis does five days from the office with desktops, not laptops. On one hand, this may seem old school, and it’s hard to find many workplaces with an inflexible work setup like this, these days.
On the other hand, Antithesis separates the office from home life with its old school setup. How often can a software engineer with a laptop truly leave work at the office? Many of us frequently take work home with us.
Debugging has been “stuck” in the 1980s. We researched how debugging techniques have evolved over the decade, and it’s striking that almost all widespread debugging techniques used today, existed from the mid-80s. Debugging has had a much smaller share of all the progress made in software engineering, over the past 40 years.
While exploring how Antithesis built their tool, it was pretty clear why it’s so hard to make progress in this field. There’s a ton of work to do to embed time-traveling debugging in existing software. And it’s practically impossible to do for third-party libraries you don’t control. The clever workaround is to enable time-traveling debugging features at the operating system level, but this is far too much work to justify for almost all software teams!
It’s exciting that there’s true innovation in debugging and testing. One thing that got us thinking, is that if Antithesis succeeds, this technology might become a platform to build products based on reproducibility, such as building more advanced debuggers, or third-party tools.
The tech is proprietary and clearly complex to build, so if Antithesis wins widespread adoption, there might be open source solutions which follow, and offer deterministic debugging to be developed by other parties.
Leveling up debugging could lead to engineering teams becoming more ambitious, and guarantee a “zero bugs” policy. Everyone knows how many bugs make it into software, and for experienced engineers, this is reason enough to not take on daunting projects like building your own database.
A reason to get excited about an ambitious “automatic debugger” like Antithesis is that it can make some highly challenging projects viable, without sacrificing quality. Imagine how much more ambitious software teams could be if they could run a simulation on their code, and that simulation would execute 99.9% of edge cases, uncovering virtually all bugs that could exist within a system.
In tech today, “zero bugs” is something more engineering teams are aiming for, as covered in the deep dive, Bug management that works. And tooling that helps simulate software and reveal more bugs, can only help to realize these ambitions.
Good luck to the Anthesis team – and to every other startup looking to innovate how we build software!
 | A guest post by
|
The section on time-travel debugging seemed a bit odd. It's a feature that comes standard with the (free) Windows SDK, and works in all languages (not just functional) on real applications (not sandboxed). This is a debugging feature that has been available for a long time in a lot of different tools, which the article didn't seem to acknowledge. Maybe Antithesis is better in some other ways, but, working outside a sandbox and not being restricted to functional languages are not differentiating factors compared to existing debugging tools.
FYI - Lisp and Prolog had these debugging technologies earlier - substantially in some cases - than the list here. Some early (~1969?) Fortran work had reversible debugging. Pretty impressive! Prolog research around 92 in particular had some very advanced capabilities around dynamic debugging and time travel that still, I think, isn't matched by the industry. That line of research tailed off after the dominance of Windows, Unix, and the AI Winter began. I can find my Masters work for citations if anyone has curiosity. :)