
Building great SDKs
A guide to creating SDKs that devs – and LLMs – will find a breeze to use, plus an overview of modern approaches for building and maintaining SDKs. By veteran SDK engineer, Quentin Pradet


Scheduling note: following this deepdive, The Pragmatic Engineer team is off on summer break. There will be no articles for the next week and a half, and one podcast episode will be published next week. Normal service resumes on Tuesday, 11 August. Taking an occasional break helps me research and write better during the rest of the year. Thank you for your understanding and ongoing support! Now, on with the latest deepdive:
As devs, we use software development kits (SDKs) to build any and all functionality for apps. Want to build a cloud service on AWS? You’ll use the AWS SDK. Integrating Stripe to an app? It will be the Stripe SDK. Doing something with Slack? You might reach for the Slack SDK.
Today, SDKs are especially relevant with AI tooling spreading across the industry, since SDKs that are easy to use are more likely to be employed by LLMs, which is an opportunity for companies offering high-quality SDKs to benefit from the “LLM wave.”
But how are great SDKs built, how much work does it take to maintain them – and why not just use an API? For answers to these questions and others, I sought out someone whose bread-and-butter is building SDKs.
Quentin Pradet is a software engineer at Elastic who maintains the Python SDKs, and has spent a decade building and maintaining SDKs. He has been the maintainer of Apache Libcloud (for interacting with cloud providers using a unified API), urllib3 (a Python library for HTTP requests), Rally (a Python benchmarking tool), and is currently the maintainer of the Python Elastisearch client.
Today, we cover:
What is an SDK? The name has stuck since SDKs were shipped on physical CD-ROMs in the 1990s.
Why build one? To simplify API usage, improve documentation, have robust error handling, and more.
How to build an SDK. The “SDK ladder”: manually-written SDKs, in-house generators, general purpose generators like AWS Smithy, Microsoft TypeSpec, and OpenAPI. As a follow-up, see the article How Elastisearch and OpenSearch built their SDKs.
API-first design process. Instead of writing code first and then creating an API for it, start with the API. It’s easy to do for new codebases / APIs, but can be tricky to retro-fit.
Can we use LLMs to generate SDKs? You might assume LLMs would shine at generating a Rust SDK based on a Java one, but the reality is different.
The day-to-day of an SDK maintainer. Answering questions, communicating with users, writing and generating documentation, and more.
SDK engineers: how many are needed? The rule of thumb used to be that one engineer can maintain one SDK. But with SDK generators, a single engineer can support SDKs written in 4-5 languages. There are limitations to take into account, though.
With that, it’s over to Quentin:
1. What is an SDK?
Historically, an SDK was a collection of development tools: documentation, libraries, frameworks, and even debuggers, which were usually distributed in CD-ROMs, back in the day:

But today, these tools are obviously no longer bundled in physical form; the software is distributed from package registries, and users – and LLMs – read their docs online. The name SDK has stuck and today refers to libraries that enable third-party developers to use a specific technology, directly. This article focuses on a specific subset: SDKs for HTTP APIs.
SDKs are different from frameworks. You can invoke them from the code you write, whereas frameworks invoke the code you write. Therefore, frameworks enforce a specific, opinionated code architecture which SDKs do not.
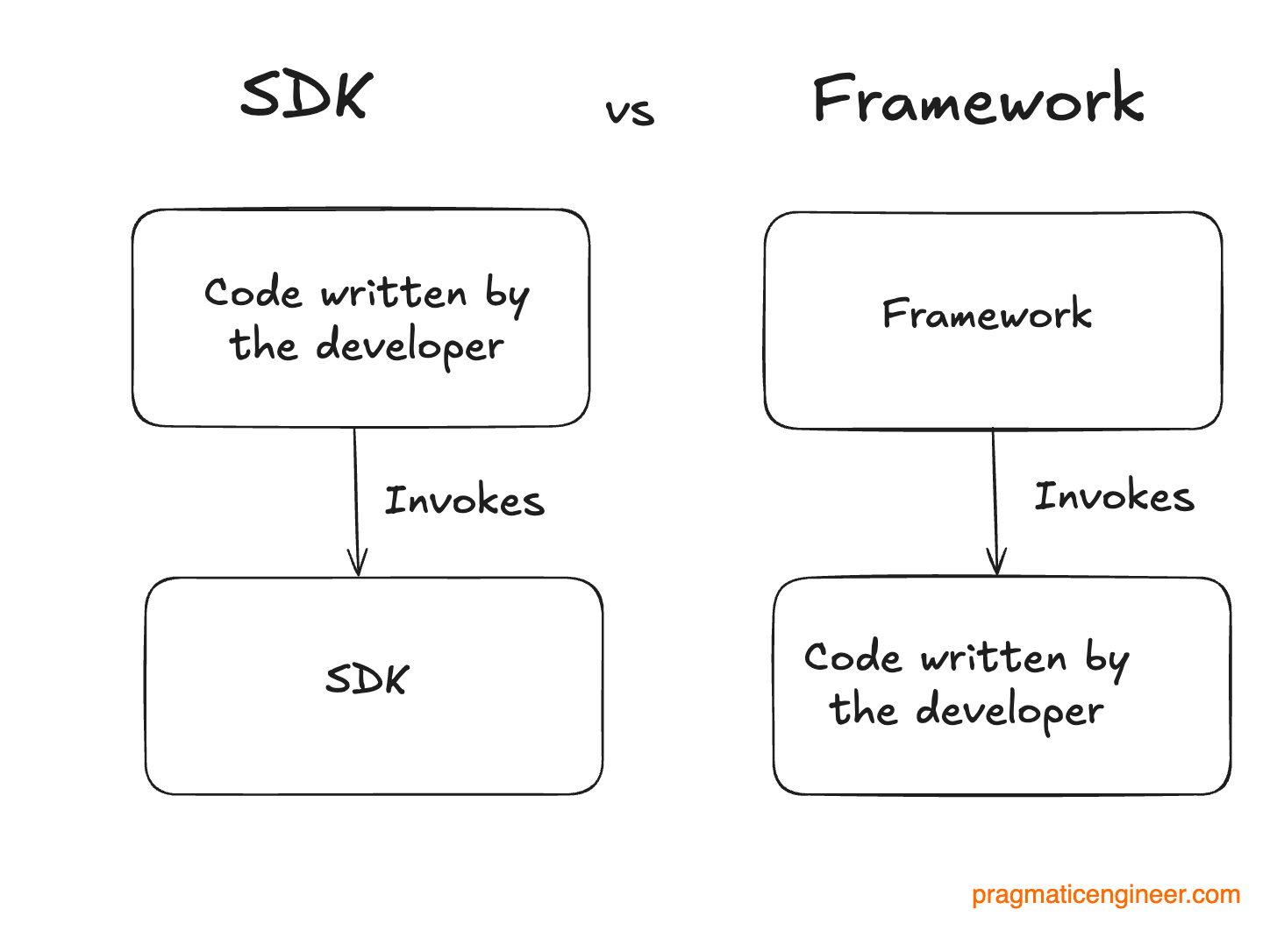
Why build an SDK for an API when there’s already an API?
The standard way to allow software engineers to integrate products is to offer an HTTP API. However, you’ll notice that some popular consumer companies provide an API without an SDK, such as the social media platform Bluesky, previously covered in the deep dive, Inside Bluesky’s engineering culture. Other companies consider an SDK so valuable that it’s built for internal-only APIs. So, what are its benefits?
Let’s take an Elasticsearch query with a few filters as an example. Without an SDK:

Below is the same query with the Elasticsearch Python client, which handles authentication, headers, and error handling. This allows you to think more about queries, and less about how to send them:

While I like the above because it hits a sweet spot between conciseness and readability for larger codebases, many of our users love the domain-specific language (DSL) module, which is even more concise and Python-like:

2. Why build an SDK?
Conciseness is one reason to build SDKs, as shown in the above example. But there are others:
Simplify API usage. Developers can explore the complete API surface from the comfort of their IDE, using autocompletion to see the options. Also, precise types give instant feedback, eliminating an entire class of errors. For example, all Elasticsearch Inference APIs are available under client.inference, and each parameter has a description and type hint. Since SDKs abstract away many concerns in calling an API, this can be done with a few simple lines of code, which helps users and LLMs.
Improve documentation. Good SDKs also include documentation tailored to the programming language, such as:
Reference documentation
Code examples
Tutorials
How-to guides
Explanations
The Diátaxis documentation framework is a good way to think about useful documentation:
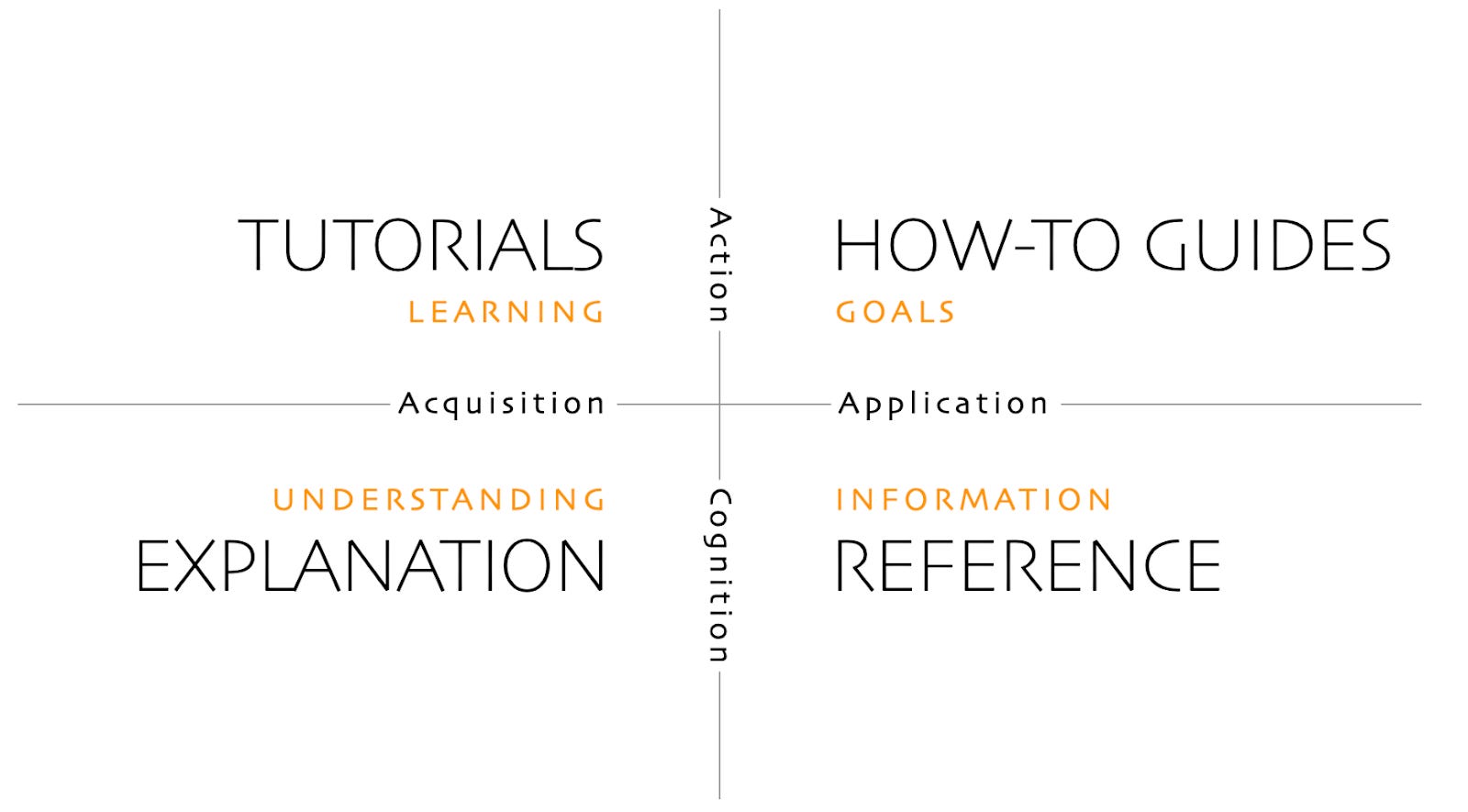
Code examples should be available in all languages, so that users and LLMs don’t have to come up with them based on generic API documentation.
Note that your docs will likely get more visits from LLMs than from people, which can be a challenge for some websites. Everything that helps users – such as code samples – will also help LLMs, but you can go one step further and provide Markdown files. Adding `.md` to any Elastic doc page will get you the Markdown source code. You can also provide a /llms.txt file to aid LLMs even more.
Robuster error handling. SDKs should raise specific exceptions/errors, allowing users to handle errors in fine-grain detail. For example, CouchDB replies to conflicts with an HTTP 409 Conflict status code, and one third-party Python SDK provides a ResourceConflict exception, which allows applications to react to conflicts easily. Additionally, for idempotent operations, SDKs can be configured to retry automatically on HTTP 429 Too Many Requests status codes, ideally using exponential backoff and jitter.
Take more advantage of language features. Maintainers with intimate knowledge of a language and its ecosystem can improve their SDK in ways that are unique to each language:
The Elasticsearch Python client supports async/await through unasync, a library that I maintain, which codegens the sync code from the async code. This is (objectively!) the best way to support async/await in Python.
JavaScript SDKs should support CommonJS / ES Modules and alternate runtimes such as Deno or Cloudflare workers.
C# database SDKs could support expression trees for strongly-typed field name access, or LINQ for simple queries.
Take care of authentication. Users only have to think of authentication as providing an API key or username/password credentials. SDKs will map this to the correct header or API call, giving clear errors on failures, and differentiating 401 and 403 status codes. For more complex cases, such as Kerberos, the Python Elasticsearch client can also delegate authentication to the Requests library.
Ensure backward compatibility. Users like nothing less than changing their code to upgrade to a newer version of an SDK: they use an SDK to make their lives easier, not harder! Keeping backward compatibility helps users to upgrade or, put differently, to avoid churn.
Backward compatibility also helps LLMs. For example, in 2021 the Python Elasticsearch client started mandating a URL scheme (http:// or https://) on instantiation, instead of just the hostname. While Claude 3.5 Sonnet always used the newer form in my tests, GPT-4o had an earlier cutoff date, and only caught up in early 2025. For this reason, software engineer Simon Willison suggests favoring popular libraries without significant changes since the training cut-off date, which differs by LLM provider.
If you need to break backward compatibility because you believe it will ultimately help users despite the short-term pain, then it’s ideal to use a long deprecation period, measured in months or years.
Better configurability support. SDKs need to adapt to user needs. After years of evolution, the Elasticsearch Python client supports nearly 50 parameters. They configure:
Authentication using 4 parameters
SSL using 9 parameters
Timeouts with 3 params
Retries with 5
Serialization with 3
Node sniffing with 10 (node sniffing is specific to Elastisearch: it’s about discovering nodes on startup and not sending requests to dead nodes
… and a few more!
All these parameters were added to help users achieve their goals. Removing them would also break backward compatibility, so needs to be done carefully. For example, Version 9 of the SDK removes parameters which had been marked for deprecation for more than 3 years.
Measure performance with built-in observability. Which of your API calls are slow? To answer this question, you should offer observability in your SDKs. While Prometheus is so widely used that you could target it directly, I recommend OpenTelemetry, which is a vendor-neutral standard, and its tooling can export metrics to Prometheus, Datadog, Honeycomb, Elastic APM, etc. Interestingly, the Python aiohttp client goes for a third approach by offering generic tracing, which grants complete control to the user, but requires custom code and is more complex to adopt.
Other reasons:
Provide helpers. These make users’ lives easier, and can add support for operations when several API calls need to be orchestrated. Examples of helpers include streaming chat completions (in the OpenAI SDK), auto-pagination (in Stripe SDKs), and bulk inserts (in the SQLAlchemy SDK).
Better serialization/deserialization. The orjson Python is an example that shines here: it encodes NumPy arrays into JSON 10x faster than the Python standard library. For best performance, you may also need to support protocols other than JSON, such as Apache Arrow.
… and more! Better integration into the ecosystem (e.g., adding LangChain integration to a vector database), supporting lower-level details (e.g. adding compression to reduce bandwidth), or domain-specific features (e.g., an Elastisearch SDK offering better node discovery with node sniffing).
Reusing an existing SDK
Sometimes, the work involved in creating an SDK can be avoided by making your API compatible with an existing one. Two typical cases are OpenAI and AWS S3, which offer SDKs in multiple languages.
Most LLM providers develop their own SDK that can utilize the full breadth of their capabilities. However, since OpenAI was the first entrant in this market, many existing applications use the OpenAI SDK, which allows targeting of any base URL. Therefore, many LLM providers support the OpenAI API in addition to their own, so customers can try models without having to rewrite their code. As a result, the OpenAI API is now a standard, supported by LLM providers such as Google Vertex, Amazon Bedrock, Ollama, and DeepSeek. These companies compete on model quality, without having to convince developers to adopt a different SDK.
Another example is AWS S3, first introduced in March 2006 – 19 years ago! Today, many storage providers claim to support the S3 API, including MinIO, Backblaze B2, Cloudflare R2, Synology, and more. However, the S3 API continues to evolve.
Recently, default data integrity protections added in their SDKs broke most S3 compatible services.
Features such as read-after-write consistency (2020), and compare-and-swap (2024) can be difficult to mimic.
As mentioned in the Elasticsearch docs, many systems claim to offer an S3-compatible API, despite failing to emulate S3’s behavior in full, which has led to some interesting Elasticsearch support cases.
Should SDKs be open source?
Yes! Simply put, this offers the best developer experience. Using only open source dependencies is a given across many platforms and industries. Nothing would be more frustrating than trying to debug an API call, then realizing you can’t see exactly what the SDK is doing, or being unable to step into a debugger. Open-sourcing an SDK can also help LLMs use it, for example by looking at integration tests. Additionally, since SDKs are aimed at developers, they’re often technical enough to be improved when needed, and to submit a change as a pull request when relevant. This is a great way to grow a community while making users happy.
What about competition, then? Even if AWS S3 and OpenAPI SDKs invite competition, making the SDKs private would hurt them more. However, anything that isn’t published to users can be kept private, as we did at Elastic with the client generators, which are not trivial to replicate.
Finally, are closed source SDKs essential to fight ad fraud? No! It’s easy to observe requests made by the SDK itself, and the intelligence of an anti-fraud system should be in the API, not the SDK.
In my opinion, SDKs should always be open source.
3. How to build an SDK
When starting an SDK, you need to decide how to build it. I like to think of the options as an “SDK ladder.” Each step requires less work to scale, at the cost of giving up some of your control:
#1: Manually-written SDKs
#2: In-house generators
#3: General-purpose generators
#4: OpenAPI generators

#1: Manually-written SDKs
For open source projects, the first SDKs are often built by community members and written manually. Since they are independent efforts, they can be incomplete, fragmented, and inconsistent with each other. This happened to Elasticsearch, and users complained about those issues, after which official clients were started in 2013.
The first version of an SDK often starts with manual coding, where an engineer writes code they think is needed to use a few APIs. They have a problem to solve and throw together a solution, and because the API surface used is small, it’s easy enough to create a high-quality SDK with high-quality code.
As the SDK grows, the limits of manually coding start to show. For example:
It becomes harder to keep up with the evolution of the APIs as engineers add more endpoints, data types, query parameters, and possible responses
Each SDK has a different level of API coverage (e.g. one SDK could lack accessing an endpoint that is exposed via the API, or support fewer query parameters than what the API exposes)
SDKs written in different languages need to be kept up-to-date with one another
#2: Custom generators
The biggest problem with manually writing code is the lack of consistency, so how can you keep several SDK clients consistent with each other? The most straightforward way is to generate all SDKs from one specification.
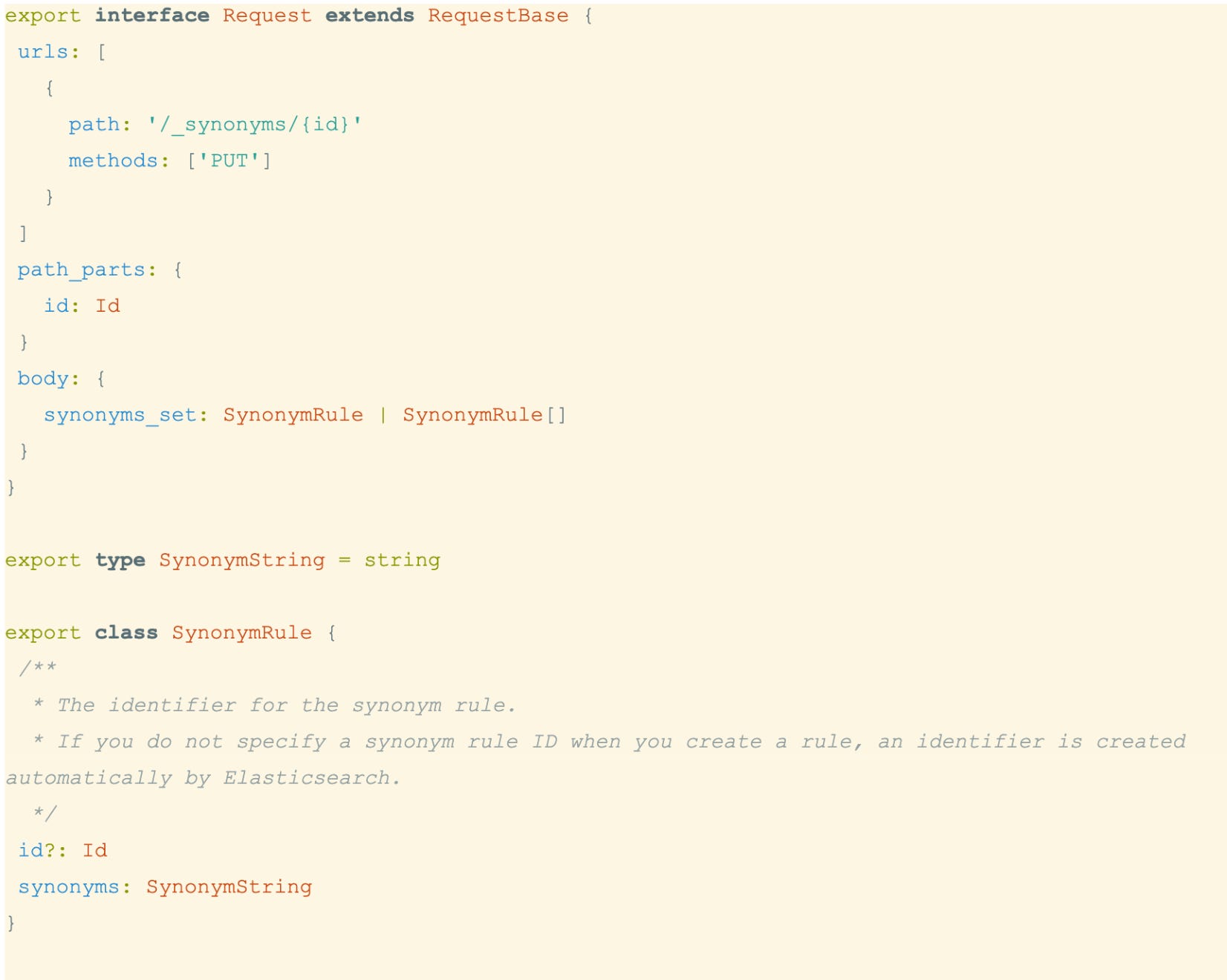
This is the approach Elastic took for Elasticsearch, whose SDKs are generated from the Elasticsearch specification. This specification defines more than 500 APIs, and each API specification is written declaratively in TypeScript. Here is an example:
From this specification, we generate a JSON file for all endpoints. This JSON file is then used by each client generator (we have one per language) to produce language-specific SDKs: eight in total.
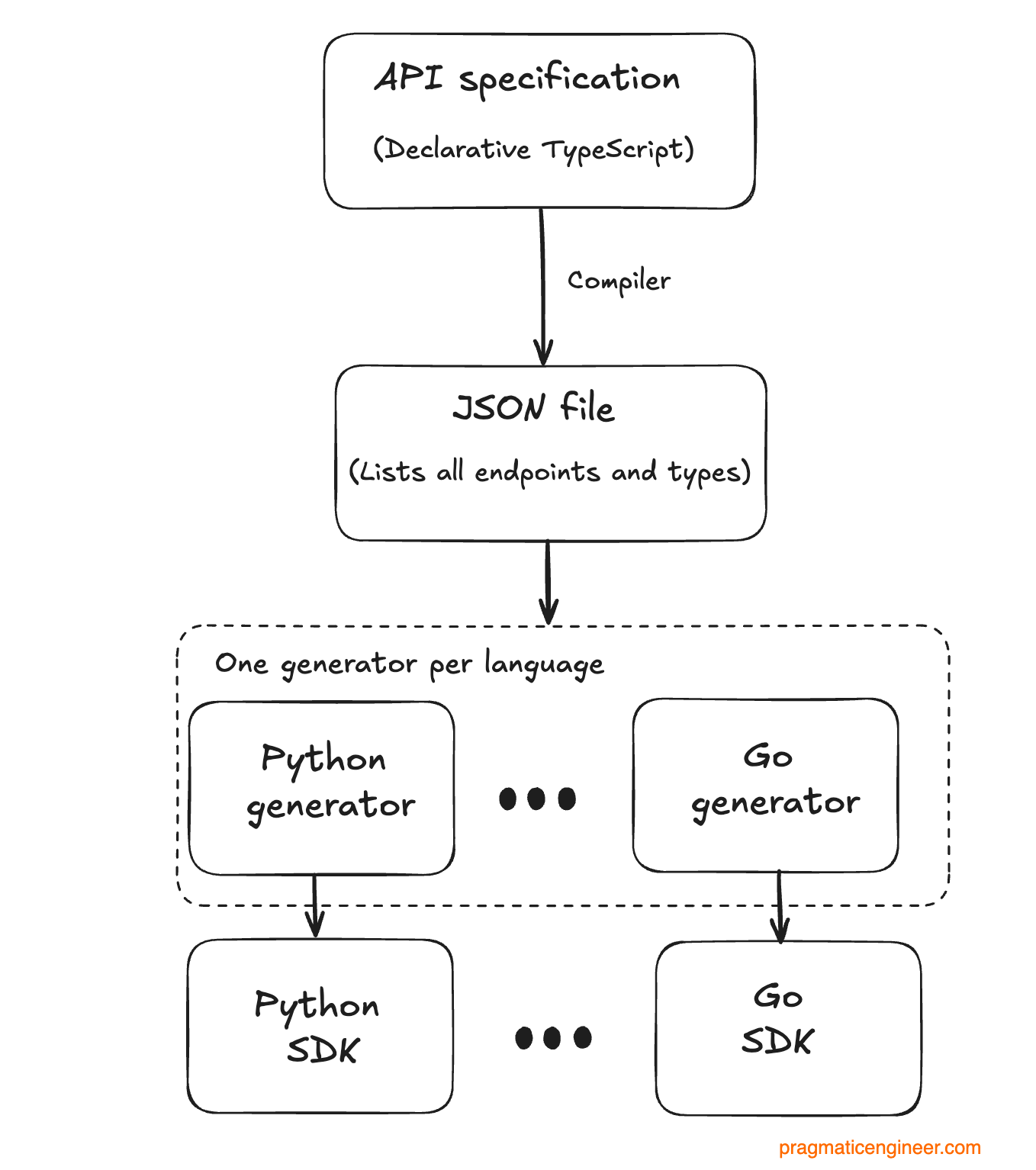
There are two big downsides to this approach:
A lot of custom code! We need to write and maintain the compiler from TypeScript to JSON, unlike with an off-the-shelf solution. Plus, we also need to maintain a custom code generator for each language. Back when building this solution, we decided that developing our own tooling was the best way to go. Companies like Stripe and Twilio also follow the custom SDK generator route, likely because suitable open source tools did not exist when they started working on their first SDKs.
The declarative TypeScript specification is maintained separately from the product. The API specification needs to be updated any time a part of the Elasticsearch API changes. Once we move over to an API-first approach (discussed below), we can discard this step.
#3: General-purpose generators: Smithy and TypeSpec
 |
|