
Applied AI Software Engineering: RAG
Retrieval-Augmented Generation (RAG) is a common building block of AI software engineering. A deep dive into what it is, its limitations, and some alternative use cases. By Ross McNairn.


👋 Hi, this is Gergely with a subscriber-only issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. To get articles like this in your inbox, every week, subscribe:
I recently spoke with Karthik Hariharan, who heads up engineering at VC firm Goodwater Capital, and he highlighted a trend he’d spotted:
“There’s an engineering project I’m seeing almost every startup building a Large Language Model (LLM) put in place: building their own Retrieval Augmentation Generation (RAG) pipelines.
RAGs are a common pattern for anyone building an LLM application. This is because it provides a layer of ‘clean prompts’ and fine-tuning. There are some existing open-source solutions, but almost everyone just builds their own, anyway.”
I asked a few Artificial Intelligence (AI) startups about this, and sure enough, all do build their own RAG. So, I reached out to a startup I know is doing the same: Wordsmith AI. It’s an AI startup for in-house legal teams that’s making heavy use of RAG, and was co-founded by Ross McNairn. He and I worked for years together at Skyscanner and he offered to share Wordsmith AI’s approach for building RAG pipelines, and some learnings. Declaration of interest: I’m an investor in Wordsmith, and the company has recently launched out of stealth.
Today, we cover:
Providing an LLM with additional context
The simplest RAGs
What is a RAG pipeline?
Preparing the RAG pipeline data store
Bringing it all together
RAG limitations
Real-world learnings building RAG pipelines
Today’s article includes a “code-along,” so you can build your own RAG. View the code used in this article at this GitHub repository: hello-wordsmith. To keep up with Ross, subscribe to his blog or follow him on LinkedIn.
With that, it’s over to Ross:
Introduction
Hi there! This post is designed to help you get familiar with one of the most fundamental patterns of AI software engineering: RAG, aka Retrieval Augmented Generation.
I co-founded a legal tech startup called Wordsmith, where we are building a platform for running a modern in-house legal team. Our founding team previously worked at Meta, Skyscanner, Travelperk and KPMG.
We are working in a targeted domain – legal texts – and building AI agents to give in-house legal teams a suite of AI tools to remove bottlenecks and improve how they work with the rest of the business. Performance and accuracy are key characteristics for us, so we’ve invested a lot of time and effort in how to best enrich and “turbo charge” these agents with custom data and objectives.
We ended up building our RAG pipeline, and I will now walk you through how we did it and why. We’ll go into our learnings, and how we benchmark our solution. I hope that the lessons we learned are useful for all budding AI engineers.
1. Providing an LLM with additional context
Have you ever asked ChatGPT a question it does not know how to answer, or its answer is too high level? We’ve all been there, and all too often, interacting with a GPT feels like talking to someone who speaks really well, but doesn’t know the facts. Even worse, they can make up the information in their responses!
Here is one example. On 1 February 2024, during an earnings call, Mark Zuckerberg laid out the strategic benefits of Meta’s AI strategy. But when we ask ChatGPT a question about this topic, this model will make up an answer that is high-level, but is not really what we want:

This makes sense, as the model’s training cutoff date was before Mark Zuckerberg made the comments. If the model had access to that information, it would have likely been able to summarize the facts of that meeting, which are:
“So I thought it might be useful to lay out the strategic benefits [of Meta’s open source strategy) here. (...)
The short version is that open sourcing improves our models. (...)
First, open-source software is typically safer and more secure as well as more compute-efficient to operate due to all the ongoing feedback, scrutiny and development from the community. (...)
Second, open-source software often becomes an industry standard. (...)Third, open source is hugely popular with developers and researchers. (...)
The next part of our playbook is just taking a long-term approach towards the development.”
LLMs’ understanding of the world is limited to the data they’re trained on. If you’ve been using ChatGPT for some time, you might remember this constraint in the earlier version of ChatGPT, when the bot responded: “I have no knowledge after April 2021,” in several cases.
Providing an LLM with additional information
There is a bunch of additional information you want an LLM to use. In the above example, I might have the transcripts of all of Meta’s shareholders meetings that I want the LLM to use. But how can we provide this additional information to an existing model?
Option 1: input via a prompt
The most obvious solution is to input the additional information via a prompt; for example, by prompting “Using the following information: [input a bunch of data] please answer the question of [ask your question].”
This is a pretty good approach. The biggest problem is that this may not scale because of these reasons:
The input tokens limit. Every model has an input prompt token limit. At the time of publication this is 4.069 tokens for GPT-3, 16,385 for GPT-3.5, 8,192 for GPT-4, 128,000 for GPT-4 Turbo, 200.000 for Anthropic models. Google’s Gemini model allows for an impressive one million token limit. While a million-token limit greatly increases the possibilities, it might still be too low for use cases with a lot of additional text to input.
Performance. The performance of LLMs substantially decreases with longer input prompts; in particular, you get degradation of context in the middle of your prompt. Even when creating long input prompts is a possibility, the performance tradeoff might make it impractical.
Option 2: fine-tune the model
We know LLMs are based on a massive weights matrix. Read more on how ChatGPT works in this Pragmatic Engineer issue. All LLMs use the same principles.
An option is to update these weight matrices based on additional information we’d like our model to know. This can be a good option, but it is a much higher upfront cost in terms of time, money, and computing resources. Also, it can only be done with access to the model’s weightings, which is not the case when you use models like ChatGPT, Anthropic, and other “closed source” models.
Option 3: RAG
The term ‘RAG’ originated in a 2020 paper led by Patrick Lewis. One thing many people notice is that “Retrieval Augmented Generation” sounds a bit ungrammatical. Patrick agrees, and has said this:
“We always planned to have a nicer-sounding name, but when it came time to write the paper, no one had a better idea.”
RAG is a collection of techniques which help to modify a LLM, so it can fill in the gaps and speak with authority, and some RAG implementations even let you cite sources. The biggest benefits of the RAG approach:
Give a LLM domain-specific knowledge You can pick what data you want your LLM to draw from, and even turn it into a specialist on any topic there is data about.
This flexibility means you can also extend your LLMs’ awareness far beyond the model’s training cutoff dates, and even expose it to near-real time data, if available.
Optimal cost and speed. For all but a handful of companies, it's impractical to even consider training their own foundational model as a way to personalize the output of an LLM, due to the very high cost and skill thresholds.
In contrast, deploying a RAG pipeline will get you up-and-running relatively quickly for minimal cost. The tooling available means a single developer can have something very basic functional in a few hours.
Reduce hallucinations. “Hallucination” is the term for when LLMs “make up” responses. A well-designed RAG pipeline that presents relevant data will all but eliminate this frustrating side effect, and your LLM will speak with much greater authority and relevance on the domain about which you have provided data.
For example, in the legal sector it’s often necessary to ensure an LLM draws its insight from a specific jurisdiction. Take the example of asking a model a seemingly simple question, like:
How do I hire someone?
Your LLM will offer context based on the training data. However, you do not want the model to extract hiring practices from a US state like California, and combine this with British visa requirements!
With RAG, you control the underlying data source, meaning you can scope the LLM to only have access to a single jurisdiction’s data, which ensures responses are consistent.
Better transparency and observability. Tracing inputs and answers through LLMs is very hard. The LLM can often feel like a “black box,” where you have no idea where some answers come from. With RAG, you see the additional source information injected, and debug your responses.
2. The simplest RAGs
The best way to understand new technology is often just to play with it. Getting a basic implementation up and running is relatively simple, and can be done with just a few lines of code. To help, Wordsmith has created a wrapper around the LlamaIndex open source project to help abstract away some complexity. You can get up and running, easily. It has a README file in place that will get you set up with a local RAG pipeline on your machine, and which chunks and embeds a copy of the US Constitution, and lets you search away with your command line.
This is as simple as RAGs get; you can “swap out” the additional context provided in this example by simply changing the source text documents!
This article is designed as a code-along, so I'm going to link you to sections of this repo, so you can see where specific concepts manifest in code.
To follow along with the example, the following is needed:
An active OpenAI subscription with API usage. Set one up here if needed. Note: running a query will cost in the realm of $0.25-$0.50 per run.
Follow the instructions to set up a virtual Python environment, configure your OpenAI key, and start the virtual assistant.
This example will load the text of the US constitution from this text file, as a RAG input. However, the application can be extended to load your own data from a text file, and to “chat” with this data.
Here’s an example of how the application works when set up, and when the OpenAI API key is configured:

If you’ve followed along and have run this application: congratulations! You have just executed a RAG pipeline. Now, let’s get into explaining how it works.
3. What is a RAG pipeline?
A RAG pipeline is a collection of technologies needed to enable the capability of answering using provided context. In our example, this context is the US Constitution and our LLM model is enriched with additional data extracted from the US Constitution document.
Here are the steps to building a RAG pipeline:
Step 1: Take an inbound query and deconstruct it into relevant concepts
Step 2: Collect similar concepts from your data store
Step 3: Recombine these concepts with your original query to build a more relevant, authoritative answer.
Weaving this together:
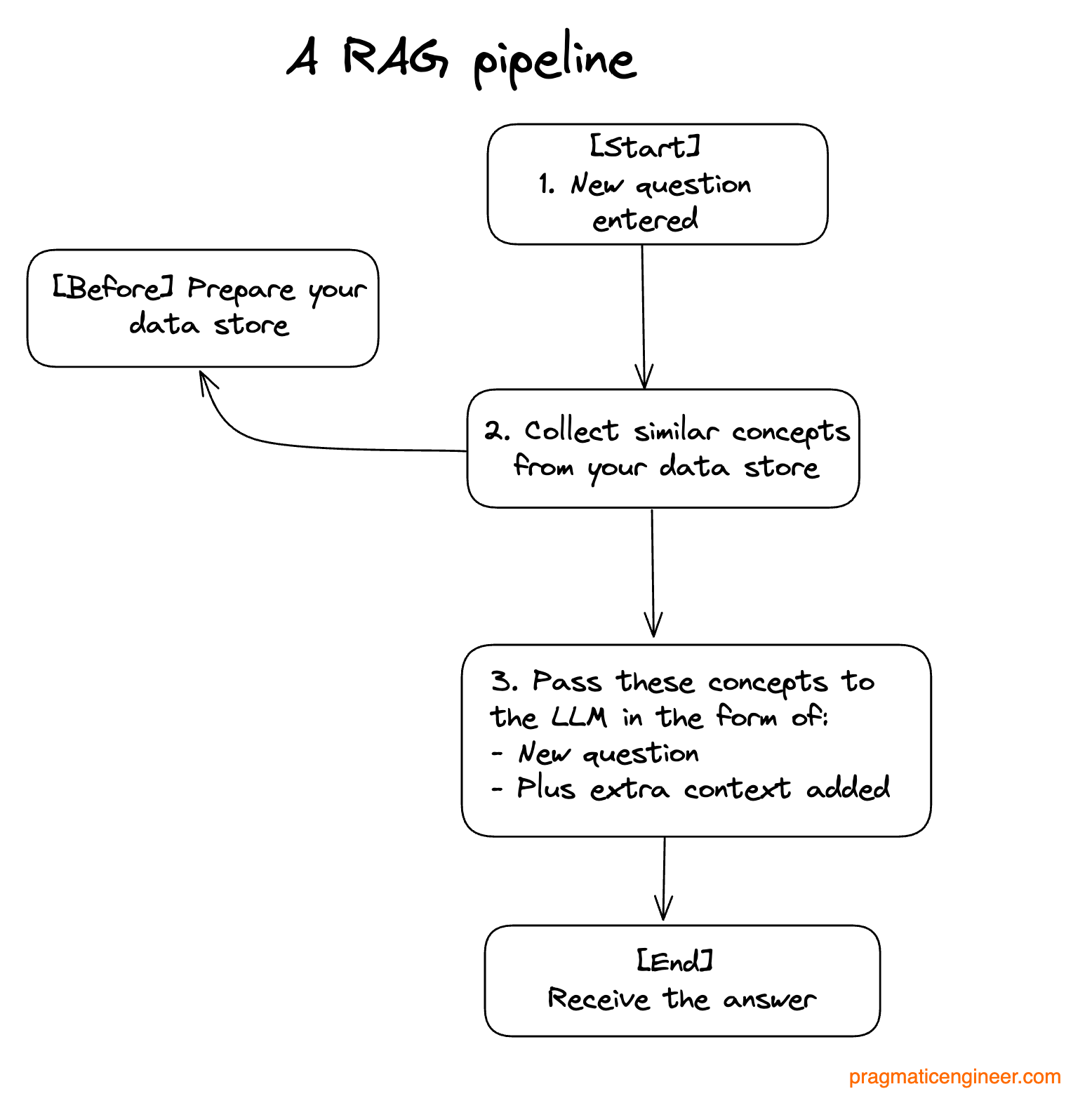
While this process appears simple, there is quite a bit of nuance in how to approach each step. A number of decisions are required to tailor to your use case, starting with how to prepare the data for use in your pipeline.
4. Preparing the RAG pipeline data store
 | A guest post by
|