
Real-World Engineering Challenges #4
What platform engineering is, microservice overload and migrating thousands of workflows.

👋 Hi, this is Gergely with a free bonus issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at big tech and high-growth startups through the lens of engineering managers and senior engineers.
Subscribe to get weekly issues - if you’re not already. It’s a good read, and the #1 technology newsletter on Substack.👇
Real-world engineering challenges is a bonus column. Each month, I share a handful of interesting engineering or management approaches in-depth, where you can learn something new by reading them, and diving deeper into the concepts they mention.
What is Platform Engineering - from DAZN
The Head of SRE at sports video streaming scaleup DAZN summarizes their Platform Engineering setup. DAZN has four platform areas:
Cloud Engineering: owns AWS tools and systems.
Developer Experience (DX): owns developer productivity, including Backstage.
SRE: owns reliability and incident response process.
Core Services: owns some of the shared services used across the company.
The article summarizes things that work well in the setup - collaboration, DX working with other platform teams, developers as customers and guidance over governance.
I especially liked how the article closed on what could be better: unclear ownership and missing frontend platforms. The most interesting missing thing was the lack of metadata about services - which teams own it, what oncall details are, and its dependencies.
Platform teams are becoming a cornerstone for any growing engineering organization to work efficiently, and it’s refreshing to see more companies share what works for them - and what doesn’t.
Forming a Frontend Platform Team at Razorpay
The previous article highlighted how the DAZN team wished they would have focused more on frontend platform in the early days. Lucky for us, the RazorPay team have published just the piece on this: sharing their approach in creating a Frontend platform team.
Razorpay’s engineering team tripled over the past two years, and they’ve started to face several issues:
Lack of infrastructure standardization
Lack of design consistency
Complicated release management
Lack of testing infrastructure
Complicated local environment setup
The team mapped out their current workflow, from setting up a project to deploying and monitoring in production. They then drew up their ideal ideal workflow which they called the Nirvana workflow. The Frontend Platform team - or Frontend Core team, as they call it - is working on making this Nirvana workflow possible.

The article goes into detail about how they are approaching both tooling, core infrastructure, and their design system.
I really liked how the article is full of specific steps the team is building, from CLI scaffolding, through automated versioning, to Server-side-rendering and monitoring/observability tooling. The article closes with things the team feels they could have done even better.
Why it’s hard to estimate food delivery times: answers from Gojek
Have you ever been annoyed at how the delivery time for your food delivery app was overly optimistic? Most of us have. So how do you build an accurate way to estimate deliveries, and how do you do this at scale?
Gojek delivers food to millions of customers in Indonesia through their GoFood delivery service. They observed that if the actual time of arrival is much higher than what was estimated, customers churn. The team behind their estimation service called Tensoba shared their approach.
This team translated the problem of predicting an ETA a Regression machine learning problem and one that is a time series problem for each merchant.
The Tensoba team defined several metrics to track:
RMSE: Root Mean Squared Error (offline metric)
MAE: Mean Absolute Error (offline metric)
MAPE: Mean Absolute Percentage Error (offline metric)
Compliance (online metric)
Conversion (online metric)
To measure how their model works, the team divided the actual time of arrival in three parts, aiming to predict all parts with various models. The parts are:
T1: time between booking order to driver arrival to the restaurant
T2: time between driver arrival to driver pickup
T3: time between driver pickup to arrival time
The rest of the article details model results and implementation details. Their approach decreased the estimation time error by 23%, and the article closes with improvement ideas.
Detecting and mitigating microservice overload at LinkedIn
What happens when you have more than 1,000 Java microservices? One problem LinkedIn faced is how some services get overloaded to the point that they cannot serve traffic with reasonable latency.
LinkedIn built Hodor - Holistic Overload Detection and Overload Remediation - a service to detect service overload, and to automatically fix the root causes. Fixing typically means dropping enough traffic for the service to recover, and then maintaining an optimal traffic level to prevent the overload from happening.
Hodor consists of the following parts:
Overload detectors: to be able to tell if a service is overloaded. These might be generic or context-specific components.
Load shedder: deciding on which traffic to drop when a detector has signaled there is too much traffic.
Adapter: a platform-specific component that converts request-specific data to a generic format that detectors and shedders can understand.
The rest of the article goes into details on detecting CPU overload, shedding requests when these happen, and how they tested Hodor and rolled it out across LinkedIn. I especially liked how the team had a mantra and changed their approach so they could stick to it:
“The mantras for the project has been to do no harm and not cause unnecessary traffic drops. To this end, we have made service analysis and evaluation a core component of our rollout process.”
Migrating 3,000 workflows to a new service at Pinterest
Pinterest decided to move from their legacy workflow system - Pinball - to an Apache Airflow-based one called Spinner. This system uses DAGs - Directed Acyclic Graph - which is a Python script representing workflows as a collection of all tasks needed to run. Their challenge was to migrate 3,000+ workflows, working with all engineering teams, and do this migration seamlessly.
Custom migration tooling is an approach Pinterest took worth taking a note of for large-scale migrations. They built a UI tool so users could migrate their existing workflows to Airflow. Without this tool, custom code would have needed to be written for each migration. With the tool, each migration was done in a few minutes. Here’s a screenshot of their tool:
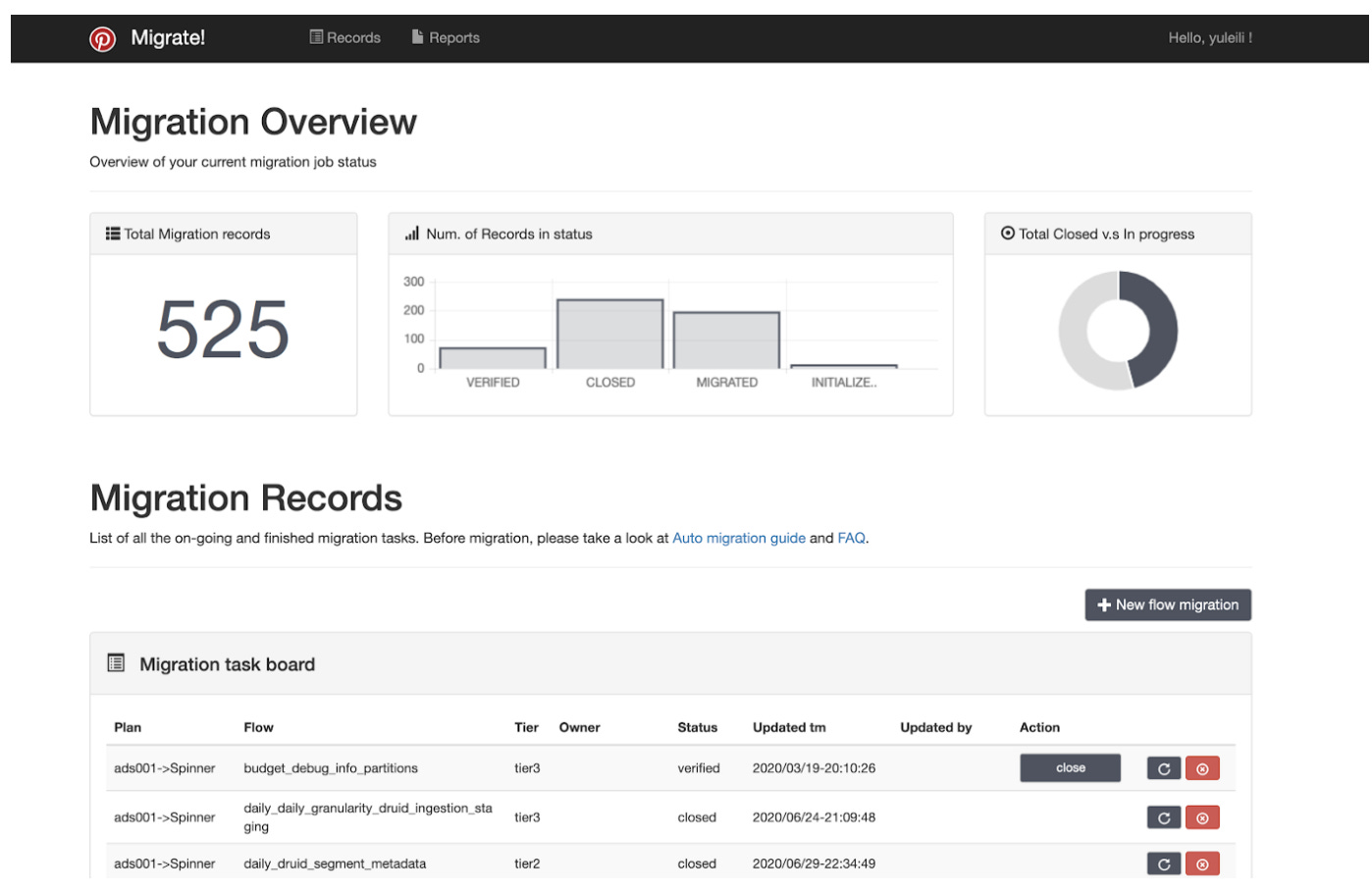
The rest of the article details the migration, from how Kubernetes pods were set up and how various pods were generated, all the way to how Pinterest measured their systems health.
How would you rate this issue? 🤔
Amazing • Great • Good • OK • So-so