
The Machine Learning Toolset
Commonly used machine learning (ML) tools, a day in the life of an ML engineer, and typical paths into the ML field.


In a previous issue, ML engineer Vicki Boykis gave us an introduction to machine learning. Today, we continue the series, and answer this question:
“Q: As a software engineer, which tools should I know for ML engineering, and how do I get into this field?”
Vicki is currently a Senior Machine Learning Engineer at Duo Security, was previously at Automattic (Tumblr, WordPress,) and has been an ML consultant. In today’s issue, she covers:
Overview of the machine learning workflow
ML at an e-commerce company
Creating a model
Common ML tools
An example of using ML tools
Day in the life of an ML engineer
How to get into the machine learning field
With that, it’s over to Vicki!
In my last article on machine learning engineering, I covered:
My background
How machine learning fits into product features
The relationship between ML and AI
In this post, I dive deeper into the tools machine learning engineers use, the day-to-day work, and cover some routes into the field.
As a refresher, a ML feature is any application feature that surfaces data which machine learning models generate. For example, Netflix’s videos and movie recommendations are surfaced as outputs of a machine learning platform. This platform has numerous recommendation models which learn users’ preferences from clickstream data. Clickstream data is the sequence of user actions, events and “clicks” that the user makes.
When you use Uber or Lyft, or make a booking on Airbnb, the chances are you’re served software components developed by ML organizations within those companies. These are very visible, consumer end-uses of machine learning. ML is also used in the less visible parts of ML organizations: for example, fraud detection at Stripe and banks, and in content moderation on social media platforms.
ML features are rarely developed only by MLEs (machine learning engineers). They typically work :
Product managers: Discussions with product about what kind of features make sense for end-users, based on company goals and metrics. A feature is then specified to product and ML requirements.
Data engineers: when data is needed to create models, it’s generally the responsibility of data engineering teams to create the infra to provide the data.
Software engineers (SWE) and site reliability engineers (SRE): SWEs and SWE teams work with MLEs (machine learning engineers) on infrastructure which scales and ship models into production environments
UX and data science: MLEs work with UX (user experience) researchers and data scientists to dig into metrics to understand how users interact with the UI (user interface) of how models are presented
1. Overview of the ML workflow
Machine learning workflows are made up of several sequential components in a loop:
Data Collection and Ingestion input data, processing it into artifacts to be used to build models
Training and Evaluation of those models and examination of their results, via statistics or online mechanisms like A/B testing.
Deployment of those models to production, including all the production components which keep models running, like monitoring, model tracking, feature tracking, dashboards, and tuning of the application’s performance.
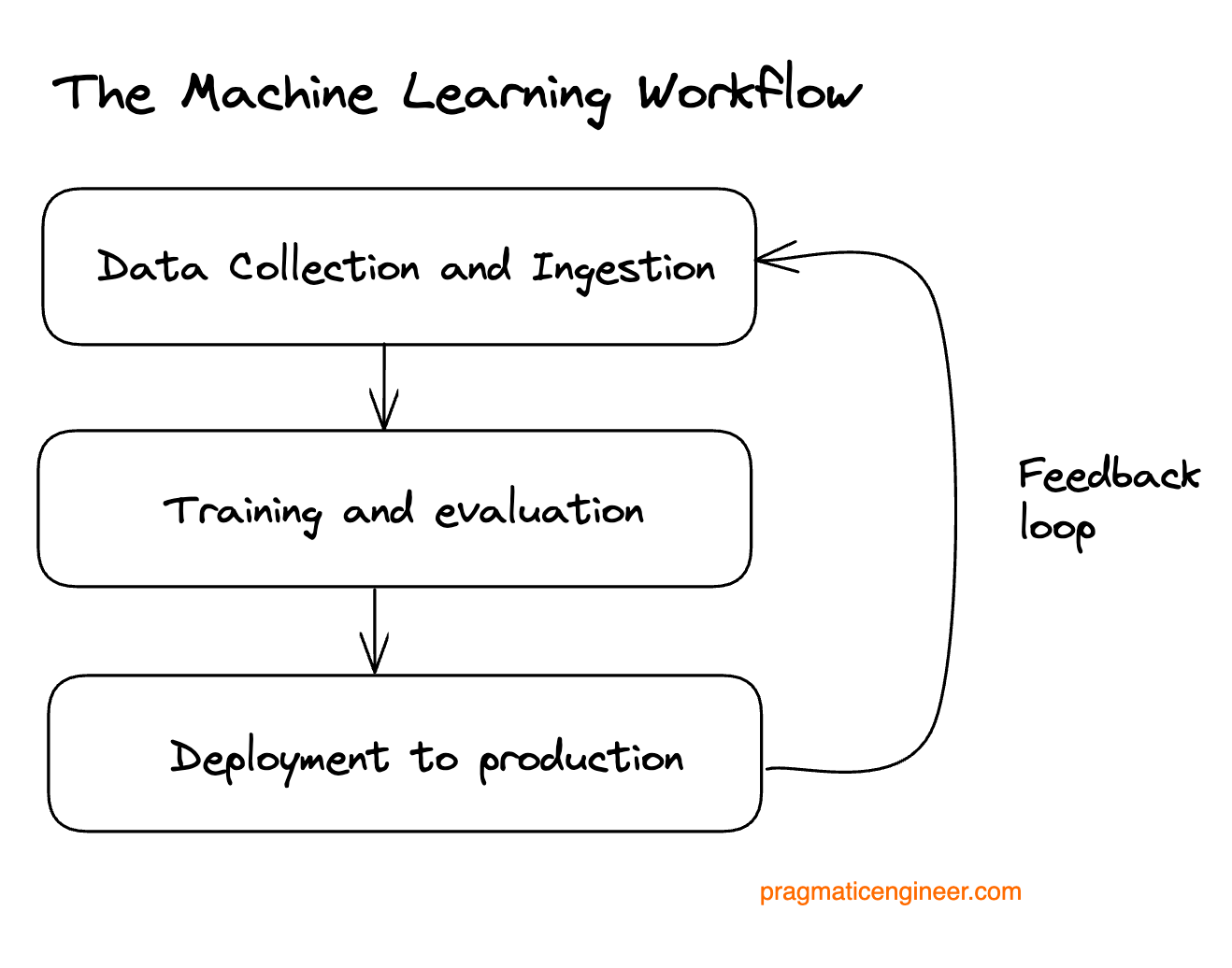
We can split ML work into two categories:
Building models: These will be used for the task at hand.
Supporting models: building infrastructure and tooling that supports the built models. This includes monitoring, a platform to track model artifacts, and workflows to develop models.
Machine learning engineers tend to work in one of two setups:
More research oriented. MLEs tend to focus on model building and offline analysis of these models, such as analyzing performance metrics before shipment as part of a product
More production oriented. MLEs tend to spend more time deploying models to production and enabling velocity in model development. MLEs in platform teams tend to be more production oriented.
2. ML at an e-commerce company
Let’s create a sample machine learning application to clearly visualize what ML engineers may do on any given part of a platform. We’ll use a fictional company called Bookmart, an international online retail platform selling books.
When Bookmart was founded as a startup, it didn’t use any ML systems and instead ran on “gut feel” and heuristics (aka business rules,) to offer customers products related to ones they were currently looking at. A good rule of thumb is to always start without machine learning systems, because building them is very time-intensive and at young companies building out ML can result in unnecessary technical debt.
However, as the business grows, it becomes clear to the product management team that machine learning can help the business. This realization was likely reached by noticing the growth in the number of hand-crafted rules being used to run the business, and realizing it would be better if these rules were ML models which can learn the rules by themselves, instead.
A customer-facing application for ML could be to personalize recommendations, let’s call the feature “Books you might like.” Prior to starting to use a machine learning system, we might display best-selling books to all customers on the site, but then notice people in different geographies prefer books in different languages. So we create separate lists for North America, Europe, Asia, and Latin America. Then, we learn that users prefer different books during summer holidays and winter break, so more rules are written for that. Later on, we decide to recommend different books during mornings and evenings.
Together, all these rules create an enormous business rules engine which takes forever to resolve and needs to be regularly manually updated. Instead of this large business rules engine, we want to offer books based on users’ preferences. And we can tease out these preferences by using an ML recommendations model known as “collaborative filtering.”
Let’s assume that after meeting the product and operations teams, the ML team decides we want the product experience in the UI to look like this:

In order to build the “Books You Might Also Like” feature, we need to do a couple of things:
Source training data from previous user activity to feed the model
Train the the model on this data
Deploy this model to production so it produces a list of book outputs for each customers as an API, then hook that API up to the front-end so the output of the model loads in the “Books You Might Also Like” section
Monitor the performance of the ML model in customer purchases from this section, and engineering metrics such as latency.
Depending on how the company works, the above scoped work could be the responsibility of a single role, which is pretty typical in smaller startups. At larger companies with bigger codebases, an entire team may be responsible for each step, or part of each step, in the above cycle.
Non-customer facing applications for ML are aplenty as the business grows. For example, we could:
Optimize the supply chain and shipping cadences using ML
Use time series forecasting to predict the next quarter sales, in order to budget appropriately
Analyze customer characteristics to predict which customers are unhappy and likely to churn
Each new use case we identify usually arises from meetings with other teams like marketing, operations, and product management.
3. Creating a model
Creating a model is an iterative process that involves collecting data, building a model artifact from that data, examining how the artifact performs on data it hasn’t seen before, and tweaking the input data. We start by taking data as input and generate a model artifact. We then feed more data into this artifact, and have this artifact output predictions.
Model artifacts are data structures typically consisting of:
 | A guest post by
|