
Building Bluesky: a Distributed Social Network (Real-World Engineering Challenges)
Bluesky is built by around 10 engineers, and has amassed 5 million users since publicly launching in February this year. A deep dive into novel design decisions, moving off AWS, and more.


👋 Hi, this is Gergely with a free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. This deepdive was written in April 2024, 6 months before Bluesky started to get 1 million new users per day, in November 2024. To read deepdives about interesting tech companies and technologies early, subscribe to The Pragmatic Engineer — it’s free:
‘Real-world engineering challenges’ is a series in which we interpret interesting software engineering or engineering management case studies from tech companies.
Bluesky is known as a Twitter-alternative. It launched two years ago, with an invite-only beta launch last year. It’s already grown to an impressive 5.5 million registered users. Interestingly for software engineers, Bluesky is also a fascinating engineering project unlike any other mainstream social network. Martin Kleppman, author of the Designing Data Intensive Applications book, is involved as a technical advisor, and has published a paper outlining the novel approaches Bluesky has taken.
The biggest differences between Bluesky and other large social networks:
Decentralized. Bluesky is a “decentralized social network,” meaning anyone can run their own servers. If Bluesky’s core team turned off all services today, the network would keep functioning. As such, Bluesky offers a way for users to truly own their data and services.
Open source. Nearly everything about Bluesky builds is open source, and hosted on GitHub.
Rapid growth. The product went from zero to 5 million users in around 12 months after announcing an invite-only beta.
Small team. Bluesky was built with a small team of 3 engineers during the first year, and with 12 software engineers at the time of publication.
Update in November 2024: Bluesky has crossed 25 million users, and employs still just 15 software engineers, and successfully keeps up with the ongoing growth. It’s rate since we saw similar growth in the past with such a small team. One example that comes to mind is Instagram in the 2010s (from my talk What’s Old is New Again):

Other social networks have achieved some of these things; such as Mastodon allowing users to own their data and identity, and Meta achieving eye-catching growth by getting 100 million users in just a week. Still, only Bluesky has pulled off them all.
Today, we dive into how Bluesky is built, sitting down with its two founding engineers: Daniel Holmgren and Paul Frazee. They take us through:
Development timeline. How Bluesky went from a vague idea with few specific details, to a decentralized social network with millions of users.
Experimentation phase. A team of 2-3 engineers prototyped for 9 months, established the development principles, and laid the groundwork for the protocol and app.
v1 architecture. An overview of Bluesky’s architecture at the launch of its public beta offering. This was a Postgres database built on top of AWS, and used Pulumi.
v2 architecture. Extending Bluesky to support “federation,” allowing users to run their own Bluesky instances.
Scaling the database layer. PostgreSQL didn’t scale with the site’s growth, so it was time to migrate. The team chose ScyllaDB and SQLite.
Infra stack: from AWS to on-prem. AWS was becoming too costly, so Bluesky moved over to dedicated data centers and bare-metal machines.
Reality of building a social network. Typical firefighting issues, Elon Musk, and outages not being “life-or-death” crises.
Read more on Bluesky’s engineering culture in Part 2. In that follow-up piece, we cover:
Unusual origins
Team.
Tech stack
Company culture
How the team operates
Engineering culture
Open source and community
See more in Bluesky’s engineering culture.
1. Development timeline
Bluesky has been in development for just over 2 years, and has been publicly available for around 12 months. Here’s the timeline:

Adding in the three phases we’ll discuss below:

Phase 1: Experimentation
The first 10 months of the project between January and October 2022 were all about exploration, and the team started to work fully in the open after 4 months. The first project the team open sourced was Authenticated Data Experiment (ADX), an experimental personal data server and a command-line client, accompanied by a network architecture overview.
In April 2022, heavy Twitter user, Elon Musk, raised the prospect of potentially acquiring the site, which created interest in alternatives to the bird app, as any major change in a market-leading social network does.
The first commit for the Bluesky mobile app was made in June 2022, and Paul Frazee worked on it. It started as a proof-of-concept to validate that the protocol worked correctly, and to aid protocol development via real-world use. Conventional wisdom says that prototypes are thrown away after serving their purpose.
However, in this case this mobile app that a single person had built, became the production app, following the unforeseen spike of interest in it caused by takeover news at Twitter. This is a good reminder that real world events can push conventional wisdom out of the window!
In October 2022, the team announced the Authenticated Transfer Protocol (AT Protocol) and the app’s waitlist, just a few days after news that Elon Musk was to acquire Twitter. This led many tweeters to seek alternative social networks, and drove a major signup spike for Bluesky’s private beta. This development put pressure on the Bluesky team to seize the unexpected opportunity by getting the protocol and app ready for beta users. See details on the AT Protocol.
Phase 2: invite-only launch and the first 1M users
In October 2022, Bluesky consisted solely of Jay Graber CEO, and two software engineers; Daniel and Paul. Engineer #3, Devin, joined the same month. Announcing the AT Protocol and waitlist generated some media buzz and Bluesky attracted more interest during this period.
In March 2023, the company was confident that the protocol and mobile app were stable enough to invite more users by sending invites.
“Blocking” was implemented in a single night. After the app opened up to more users, there was an influx of offensive posts and of users verbally harassing other accounts. This made it clear that implementing blocks to restrict individual accounts from viewing and commenting on a user’s posts, was urgently-needed functionality.
The three earliest developers – Paul, Devin and Daniel – jumped on a call, then got to work. In the community, developers saw the pull requests (PRs) on this feature appear on GitHub, and started to point out bugs, and cheer on the rapid implementation. They wrapped it up and launched the feature by the end of the same day. To date, this is the most rapidly-built feature, and is still used across the protocol and the app!
In June 2023, Bluesky passed the 100,000-users milestone when the team numbered 6 developers, who’d shipped features like custom feeds, blocking and muting, moderation controls, and custom domains. A web application built on React Native was also in production.
In September 2023, Bluesky passed 1 million users – a 900,000 increase in just 3 months!
Phase 3: Preparing for public launch
In the 6 months following the 1 million-user milestone, the focus was on preparing to open up Bluesky to the public with no waitlist or throttling of invites.
Federation (internal.) To prepare for “proper” federation, the team made architecture changes to enable internal federation of Bluesky servers.
Federation is a key concept in distributed networks. It means a group of nodes can send messages to one another. For Bluesky, it meant that – eventually – users should be able to run their own PDS instances that host their own user information (and user information of users on that server.) And the Bluesky network operates seamlessly with this distributed backend.
A new logo and a reference to Twitter. The team prepared a new logo for launch, and announced it in December 2023:

The butterfly logo is intended as a symbol of freedom and change. Existing centralized social media platforms – like X (formerly Twitter,) Instagram, TikTok, and Youtube – are platforms that want to lock users into their website and apps. Bluesky, on the other hand, offers its protocol, but doesn’t dictate which apps or websites people use. It doesn’t even want to dictate the hosting of content:

Let’s dive into each phase of the building process.
2. Experimentation phase
During Bluesky’s first 9 months (January-September 2022) two software engineers built the protocol and apps – Daniel Holmgren and Paul Frazee – and Jay the CEO signed off design decisions. The first couple of months were about experimenting and tech “spiking,” which means timeboxing the time and effort spent building and trying out ideas. Here’s Paul:
“We would greenfield for a period, then attack what we had just created to see if it holds up. We gave the existing technologies a really close look; if we didn’t see meaningful improvements from the existing protocols, then we decided we’d use what was already out there.”
When the direction wasn’t clear, the team kept trying out new approaches, says Daniel:
“We set out to use as many existing specs as we could. We spent a lot of time early on investigating things like Activity Pub and seriously trying to figure out how we could make it work, and realizing that it didn't really work for our use case.”
Development principles
The still-small team set up principles to ensure continuous progress:
No backward steps. Ease of use, scale, and feature developer experience, can not be worse than existing social networks’.
Unify app development with protocol development. Never make tech decisions in isolation from practical use cases.
Don’t be precious! If an idea or design doesn’t work, just throw it out!
Approach to building a new, novel decentralized protocol
The team prioritized flexible design choices in order to not lock themselves into a technology, until they knew exactly what they were building. Not coupling the data layer too closely with Postgres is an example of this. See below.
Building for flexibility, not scalability, was deliberate. The idea was to swap this approach to prioritize scale once everyone knew exactly what to build. The knowledge that decisions are hard to undo made the team’s own decision-making more thorough, Daniel reflects:
“The most difficult part of building Bluesky has been the constant awareness that small decisions you make may be locked in for years and have ripple effects. In a decentralized environment, these can be difficult to unwind. It puts a lot of weight on every decision, and we have to double and triple check choices that we make so that we hopefully don’t regret them.”
Inventing new approaches was never a goal. The original idea was to take a protocol or technology off the shelf, and push it as far as possible to reveal a requirement that didn’t quite fit. For example, Lexicon – the schema used to define remote procedure call (RPC) methods and record types – started out as JSON schemas. The team tried hard to keep it lightweight, and stuck to JSON schemas. But they ended up bending over backwards to make it work. In the end, the team decided to fork off from JSON schemas and added features to it, which is how Lexicon was born.
Bluesky gets criticism for inventing new approaches which are non-standard across decentralized networks. Paul explains it like this:
“We never set out to live the ‘not invented here’ (NIH) syndrome. I don’t think anyone building something new has this goal. In the end, it just naturally evolved in this direction.
No one had done a high-scale decentralized social network before this! If someone had, we probably wouldn’t have needed to invent as many things.”
Bluesky takes inspiration from existing web technologies. As Daniel puts it:
“The AT Protocol is a pretty typical JSON API collection over HTTP. The architecture of Bluesky looks very similar to a traditional social media data center turned inside out. The firehose API looks a lot like Kafka – and we’re probably going to shard it in a similar way.”
3. v1 architecture: not really scalable and not federated – yet
Infrastructure choices
PostgreSQL was the team’s database of choice when starting development. Postgres is often called the “Swiss Army knife of databases” because it’s speedy for development, great for prototyping, with a vast number of extensions. One drawback is that Postgres is a single bottleneck in the system, which can cause issues when scaling to handle massive loads that never materialize for most projects.
For the team, using Postgres worked really well while they were unsure exactly what they were building, or how they would query things. Paul’s summary of the choice to use Postgres:
“You start with a giant Postgres database and see how far that can take you, so that you can move quickly early on.”
AWS infrastructure was what the team started with because it’s quick to set up and easy to use, says Daniel:
“We were running everything out of AWS, and that is great because you can just spin up new VMs very easily, and spin up new stacks and services easily.”
The first infra hire at Bluesky, Jake Gold, iterated on the AWS setup:
“The basic idea we have right now is we’re using AWS, we have auto-scaling groups, and those auto-scaling groups are just EC2 instances running Docker Community Edition (CE) for the runtime and for containers. And then we have a load balancer in front and a Postgres multi-availability zone instance in the back on Relational Database Service (RDS). It’s a really simple setup.”
To facilitate deployments on AWS, the team used infrastructure-as-code service, Pulumi.
Modularizing the architecture for an open network was an effort the team kicked off early. The goal of modularization was to spin out parts of the network which users could host themselves. Daniel says:
“Our early insight was that we should give developers building on top of Bluesky the ability to focus on the parts of the network that they want to focus on. This is the microservices part.
An external developer building a feed should not need to index every “like” in the network. Someone self-hosting their own account should not need to consume thousands of posts to create a timeline. You can split the network into specific roles and have them work in concert.”
Personal Data Server
At first, the architecture of Bluesky consisted of one centralized server, the PDS (Personal Data Server.)

The strategy was to split this centralized service into smaller parts and allow for federation, eventually.
Bluesky being a federated network means individual users can run their own “Bluesky instance” and curate their own network.
The feed generator

In May 2023, the Bluesky team moved the feed generator to its own role. This service allows any developer to create a custom algorithm, and choose one to use. Developers can spin up a new Feed Generator service and make it discoverable to the Bluesky network, to add a new algorithm. Bluesky also allows users to choose from several predefined algorithms.
The Feed Generator interface was the first case of Bluesky as a decentralized network. From then, the Bluesky network was not solely the services which the Bluesky team operated, it was also third-party services like Feed Generator instances that plugged into the Bluesky network.
Dedicated “Appview” service
For the next step, the view logic was moved from the PDS, to an “Appview” service. This is a pretty standard approach for backend systems, to move everything view-related to its own service, and not to trouble other systems with presenting data to web and mobile applications.

Relays to crawl the network
In the future, there could be hundreds or thousands of PDSs in the Bluesky network. So, how will all the data be synchronized with them? The answer is that a “crawler” will go through all these PDSs. In preparation for this crawl the team introduced a Relay service:

4. v2 architecture: scaleable and federated
The v1 architecture needed to evolve in order to support full federation, and the team always planned to move on from it. But they expected v1 to last longer than only 6 months.
Federation
Federation sandbox. Before shipping a first version of federation, the team built a Federation Sandbox to test the architecture, as a safe space to try new features like modulation and curation tooling.
Internal federation. To prepare for federation proper, the next refactoring was to add support for multiple Personal Data Servers. As a first step, the Bluesky team did this internally. Users noticed nothing of this transition, which was intentional, and Bluesky was then federated! Proving that federation worked was a large milestone.
As a reminder, federation was critical to Bluesky because it made the network truly distributed. With federation, any user can run their own Bluesky server.
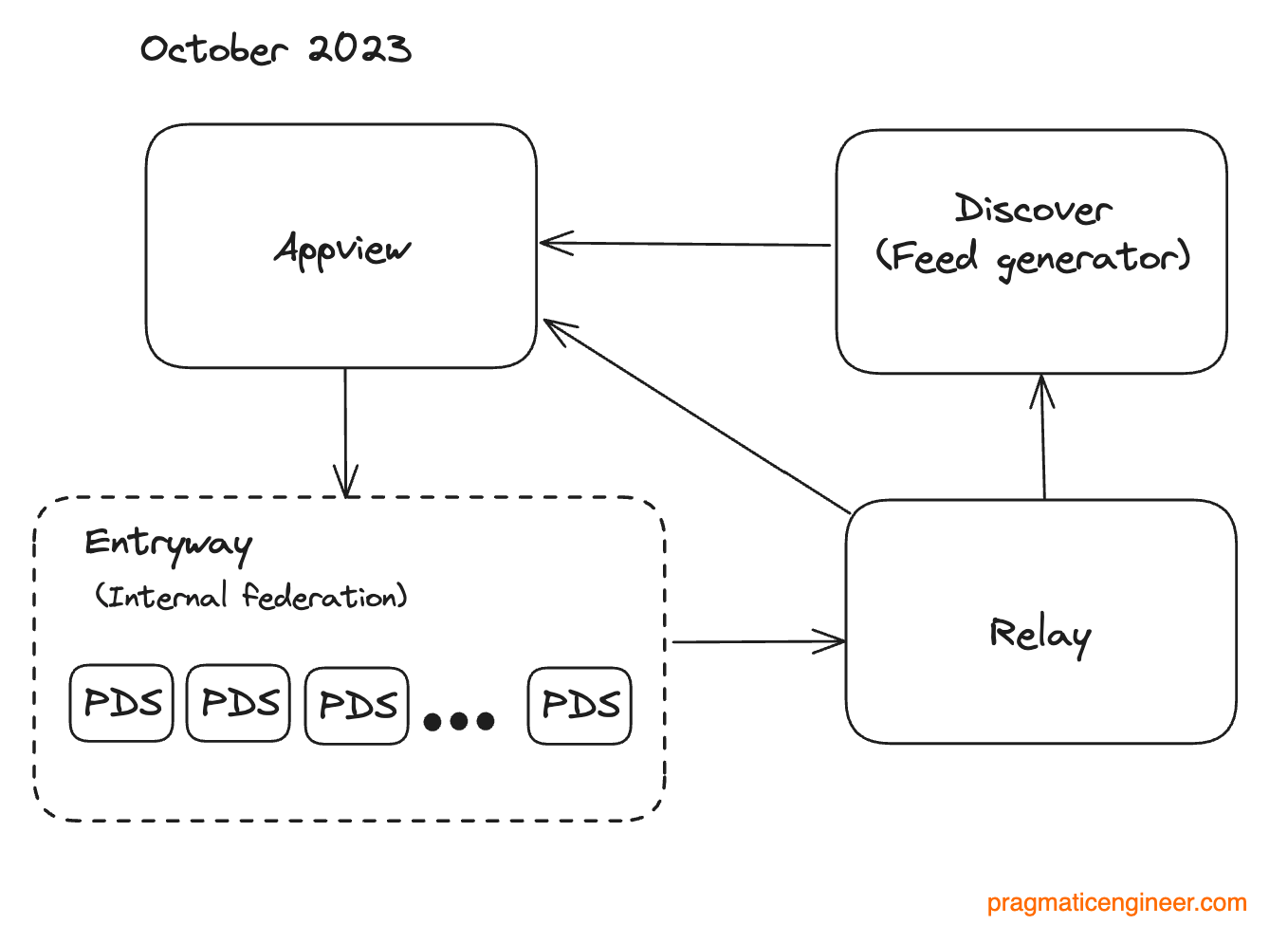
The “internally federated” PDS servers worked exactly like a self-hosted PDS. Bluesky made one addition, to wrap the internal PDS servers into a new service called “Entryway,” which provides the “bsky.social” identity to the PDSes. Entryway will become the “official” Bluesky OAuth authorization server for users who choose bsky.social servers, and one operated as a self-hosted server.
Later, Bluesky increased the number of internal PDS servers from 10 to 20 for capacity reasons, and to test that adding PDS servers worked as expected.
External federation. With everything ready to support self-hosted Personal Data Servers, Bluesky flipped to switch, and started to “crawl” those servers in February 2024:

To date, Bluesky has more than 300 self-hosted PDSs. This change has made the network properly distributed, anyone wanting to own their data on Bluesky can self-host an instance. Over time, we could also see services launch which self-host instances and allow for full data ownership in exchange for a fee.
Appview: further refactoring
Recently, Bluesky further refactored its Appview service, and pulled out the moderation functionality into its own service, called Ozone:
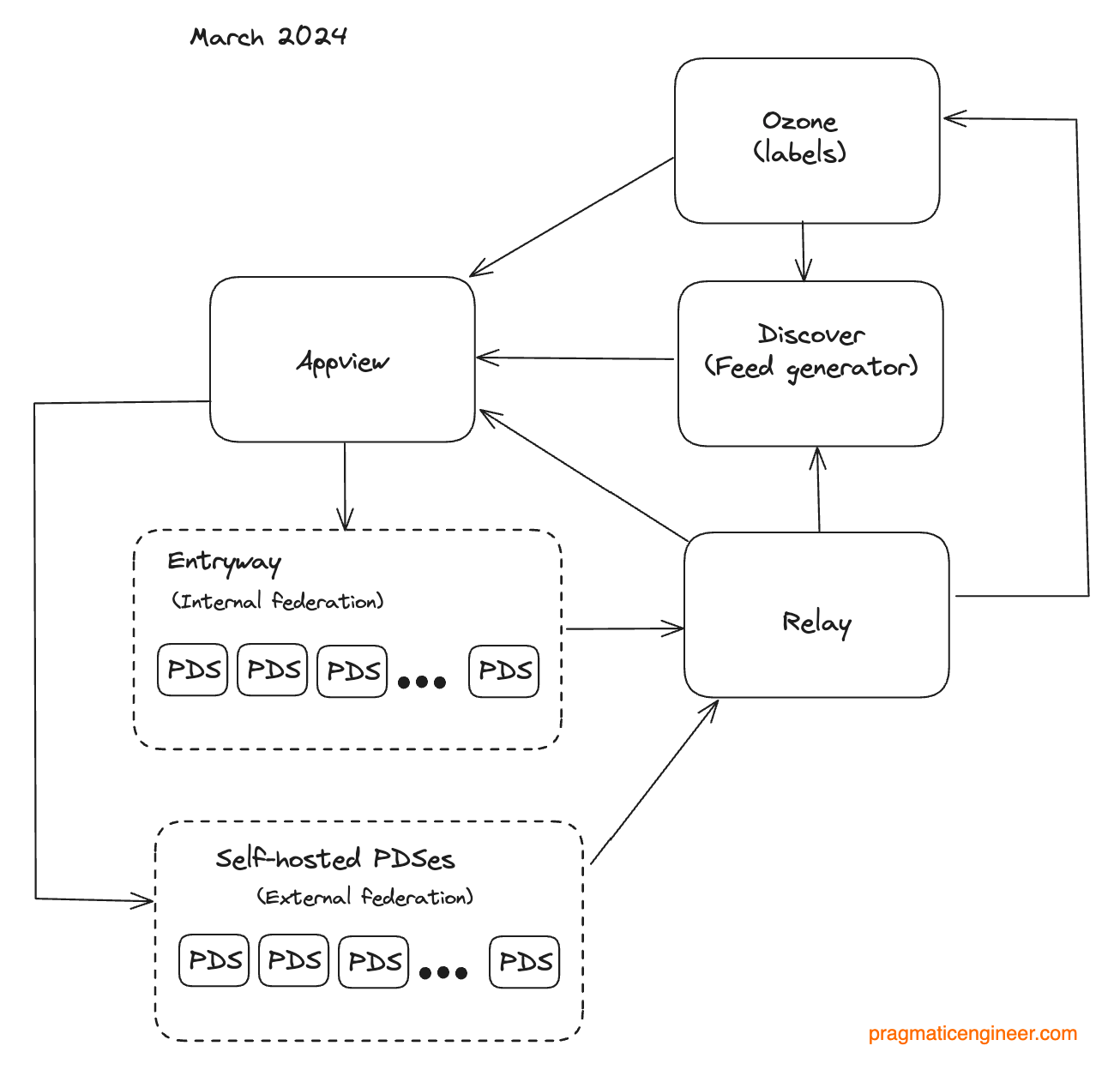
Users can run their own Ozone service – meaning to be a moderator in the Bluesky system. Here are details on how to self-host this service, and more about Ozone.
An architectural overview, with Martin Kleppman
Martin is the author of the popular software engineering book, Designing Data Intensive Applications, and he also advises the Bluesky team in weekly calls.
Martin and the Bluesky team published a paper describing the Bluesky system, Bluesky and the AT Protocol: Usable decentralized social media. In it, they offer a detailed overview of the architecture:

The diagram above shows how data flows occur in the application:
Personal data server (PDS): these can be Bluesky-hosted (around 20 today) or self-hosted (around 300)
Relays: these collect events from the PDSs. Bluesky has its “official” relay hosted in its own infrastructure, but other developers can set up alternative relays that listen to all PDSs.
Firehose: the output of the relays.
Labelers and feed generators: these digest firehose events. They can be Bluesky-hosted, or be hosted independently of Bluesky.
App View: The Bluesky-hosted “official” app view, or alternate app views
Data flowing back to PDSs: feed generators hosted by Bluesky or externally, feed events data back to the PDSs.
5. Scaling the database layer
Scaling issues with Postgres
Scaling issues emerged 2-3 months after the public beta launch in mid-2023.
Connection pool issues and lock contention. The Postgres connection pool backup and Node’s event loop got into a bad feedback loop. The team observed Postgres lock contention issues. This refers to multiple processes trying to access the same data simultaneously, but the data is locked to all except one process. For example, when multiple processes attempt to update the same row.
Small Postgres outages. Postgres doesn’t give the developer much control over which query plan it will take. Bluesky had a few smaller outages due to a query plan randomly flipping to something that ran about 1,000x times slower.
The need for horizontal scaling. Horizontal scaling is adding more machines to a service, so that the throughput of this system improves linearly with each new machine. But Postgres does not support horizontal scaling because it runs as a single database with transactional guarantees, meaning it becomes a bottleneck – if a necessary one – for the entire network.
As a reminder, the team was still tiny when all these scaling challenges emerged. There were only 6 developers (Daniel, Devin, Bryan and Jake on the backend, and Paul and Ansh on the frontend). Then in summer 2023, Daniel had a dream:
“After one stressful day, I dreamt that me, Jay [Bluesky’s CEO], and Devin were in my backyard. There were snakes everywhere you looked. We were going to wrangle and round up the snakes in a panic. But that that point, Devin stops and says to all of us: ‘wait, wait, guys, I think there’s a Postgres extension for this!’”
ScyllaDB replacing Postgres
The team knew they needed a horizontally scalable data storage solution, with fine-grained control of how data is indexed and queried.
ScyllaDB was an obvious choice because it supports horizontal scalability due to being a wide-column database (a NoSQL type.) Wide-column databases store data in flexible columns that can be spread across multiple servers or database rows. They can also support two rows having different columns, which gives a lot more flexibility for data storage!

The biggest tradeoffs:
Data must be denormalized, meaning it isn’t stored as efficiently as in a relational database. Basically, you’ll store more data and require more storage space.
Data needs to be indexed on write. Writing to a wide column database is more expensive than to a relational database. For each row and column changed, the relevant indexes need to be updated, which typically makes these databases more write-intensive than relational ones.
The team was satisfied with their early choice of Postgres, says Daniel:
“Postgres was great early on because we didn’t quite know exactly what questions we’d be asking of the data. It let us toss data into the database and figure it out from there. Now we understand the data and the types of queries we need to run, it frees us up to index it in Scylla in exactly the manner we need and provide APIs for the exact queries we’ll be asking.”
SQLite
ScyllaDB is used for the Appview, which is Bluesky’s most read-heavy service. However, the Personal Data Servers use something else entirely: SQLite. This is a database written in the C language which stores the whole database in a single file on the host machine. SQLite is considered “zero configuration,” unlike most other databases that require service management – like startup scripts – or access control management. SQLite requires none of this and can be started up from a single process with no system administrative privileges. It “just works.”
Daniel explains why SQLite was ideal for the PDSs:
“We took a somewhat novel approach of giving every user their own SQLite database. By removing the Postgres dependency, we made it possible to run a ‘PDS in a box’ without having to worry about managing a database. We didn’t have to worry about things like replicas or failover. For those thinking this is irresponsible: don’t worry, we are backing up all the data on our PDSs!”
SQLite worked really well because the PDS – in its ideal form – is a single-tenant system. We owned up to that by having these single tenant SQLite databases.
We also leaned into the fact that we’re building a federated network. We federated our data hosting in the exact same manner that it works for non-Bluesky PDSs.”
Migrating the PDSs from Postgre to SQLite created fantastic improvement in operations, Daniel adds:
“PDSs have been a dream to run since this refactor. They are cheap to operate (no Postgres service!) and require virtually no operational overhead!”
6. Infra stack: from AWS to on-prem
Bluesky’s infrastructure was initially hosted on Amazon Web Services (AWS) and the team used infrastructure-as-a-code service, Pulumi. This approach let them move quickly early on, and also to scale their infra as the network grew. Of course, as the network grew so did the infrastructure bill.
Move to on-prem
Cost and performance were the main drivers in moving on-prem. The team got hardware that was more than 10x as powerful as before, for a fraction of the price. How was this decision made? A key hire played a big role.
Bluesky’s first hire with large-scale experience was Jake Gold, who joined in January 2023, and began a cost analysis of AWS versus on-prem. He eventually convinced the team to make this big change.
But how did the team forecast future load, and calculate the hardware footprint they’d need? Daniel recalls:
“We looked at the trends and tried to make a safe bet. We were thinking: ‘okay, today we're over-provisioned. We want to stay over-provisioned, so we have room to grow without upgrading the hardware, but also just so we have stability if something happens in the world, and everyone decides to post about it.’
We built our architecture to be horizontally scalable so that we can add more capacity just by throwing more machines at it. There is some lead time to buying new machines, but we have space in the rack. We have room in the network connections. The switches are good for it.
If we need to scale, it’s really just about ‘get some more servers and hook them up!’ We can get to twice the capacity after doubling the machines we’re running in our data center. This is sweet!”
Becoming cloud-agnostic was the first step in moving off AWS. By June 2023, six months after Jake joined, Bluesky’s infrastructure was cloud agnostic.
Bluesky always has the option of using AWS to scale if needed, and is designed in a way that it would not be overly difficult to stand up additional virtual machines on AWS, if the existing infrastructure has capacity or scaling issues.
Today, the Personal Data Servers are bare-metal servers hosted by cloud infrastructure vendor, Vultr. Bluesky currently operates 20 and shards them so that each PDS supports about 300,000 users.
Bluesky’s load by the numbers
Currently, Bluesky’s system sees this sort of load:
60-100 events/second received by the firehose service, which is the “main” service that emits messages sent on the network in real time. During the public launch of Bluesky in February, the peak was 400 events/second.
400 timeline loads/second. A timeline load is when a user (or client) makes a request to fetch their current timeline.
3,500 requests/second across the network.
7. Reality of building a social network
To close, we (Gergely and Elin) asked the teams some questions on what it’s like to build a high-growth social network.
What is a typical firefighting issue you often encounter?
“Every influx of users brought new problems, and we found ourselves doing quite a bit of firefighting. One day, after a particularly notable incident, growth showed no signs of stopping, and we had to temporarily disable signups in order to keep the service running.” – Daniel
What were the events referred to as “Elon Musk?”
“We never quite knew when a user bump was going to come, and invites were out in the wild waiting to be used. Then something would happen, and thousands of users suddenly joined. We started referring to these days as EMEs (Elon Musk Events) because they were normally precipitated by some change on Twitter.” – Daniel
“It was a bit like throwing a party and everybody showing up 2 hours early, while you’re still setting up the chairs and telling people to get drinks from the fridge. And then about ten times more people show up than expected.” – Paul
How are outages different for a social network?
“Disabling signups or pausing the service is never fun to do, but it actually created a bunch of excitement and a strange sense of pride in the user base.” – Daniel
“Outages are not fun, but they’re not life and death, generally. And if you look at the traffic, usually what happens is after an outage, traffic tends to go up. And a lot of people who joined, they’re just talking about the fun outage that they missed because they weren’t on the network.” – Jake
The whole developer team is on Bluesky, and actively responding to user feedback. How do you do this, and why?
“People just pinging us in the app and explaining their problem, is so good. We can just respond, "Hey, can you give me a screenshot? What platform are you on?" It's such a fast support turnaround. The big benefit of building a social app is that your customers are right there, and will tell you if something's not working.
Real time user feedback was how mute words got prioritized, recently. In terms of a signal about how important something is, when you start getting PRs to add the feature, and you get a ton of people plus-oneing the issue – not to mention people asking for it in the app – that tells you a lot.” – Paul
Takeaways
Gergely here. Many thanks to Daniel and Paul for part one of this deep dive into how Bluesky works! You can try out Bluesky for yourself, learn more about Bluesky’s AT Protocol, or about its architecture. And I’m also on Bluesky.
Decentralized architectures require a different way of thinking. I’ll be honest, I’m so used to building and designing “centralized” architecture, that the thought of servers being operated outside of the company is very alien. My immediate thoughts were:
Is it secure enough? Malicious actors could run anything on those servers and attempt to overload the network or exploit vulnerabilities in the system. The Bluesky team also stressed how the security model is something you thoroughly need to consider as you design APIs for such a system.
What about external nodes that don’t ever update the version of the software? How do they get bug fixes? And what about versioning? How to ensure “outdated clients” are cut off from the network?
Finally, I thought; “wow, this kind of reminds me of the confusion I initially felt about Skype’s peer-to-peer network”
I’m delighted we did a deep dive about Bluesky because it has forced me to think more broadly. A server drawing on a diagram no longer just means “a group of our servers,” it can also mean “plus, a group of external servers.” Once this is understood, it’s easy. And this skill of designing distributed and federated systems may be useful in the future, as I expect the concept of distributed architecture to become more popular.
It’s impressive what a tiny team of experienced engineers can build. I had to triple-check that Bluesky’s core team was only two engineers for almost nine months, during which time they built the basics of the protocol, and made progress with the iOS and Android apps. Even now, Bluesky is a very lean team of around 12 engineers for the complexity they build with and the company’s growth.
In the next part of this deep dive into Bluesky, we cover more on how the team works.
Owning your own infrastructure instead of using the cloud seems a rational choice. Bluesky found large savings by moving off AWS once they could forecast the type of load they needed. Jake Gold, the engineer driving this transition, has been vocal about how cloud providers have become more expensive than many people realize. Speaking on the podcast, Last Week in AWS, he said:
“With the original vision of AWS I first started using in 2006, or whenever launched, they said they would lower your bill every so often, as Moore’s law makes their bill lower. And that kind of happened a little bit here and there, but it hasn’t happened to the same degree as I think we all hoped it would.”
Don’t forget, it’s not only Bluesky which rejects cloud providers for efficiency. We previously did a deep dive into travel booking platform Agoda, and why it isn’t on the cloud.
I’m slowly changing my mind about decentralized and federated social networks. I also tried out Mastodon, which is another federated social network, when it launched. At the time, Mastodon felt a lot more clunky in onboarding than Bluesky. You had to choose a server to use, but different servers have different rules, whereas Bluesky was much smoother. Still, as a user, I was blissfully unaware of how different these social networks are from the dominant platforms.
It was only by learning about Bluesky’s architecture that I appreciated the design goals of a decentralized social network. Currently, mainstream social networks are operated exclusively by the company that owns them. But a decentralized network allows servers to be operated by other teams/organizations/individuals. This might not seem like a big deal, but it means a social network is no longer dependent on the moderation policies of a parent company.
Decentralized social networks also allows users to use custom algorithms, websites and mobile apps, which creates opportunities for developers to build innovative experiences. In contrast, you cannot build a custom third-party client for X, Threads, or LinkedIn.
I’m still unsure how much mainstream appeal decentralized social networks hold for non-technical people, but I’m rooting for Bluesky, Mastodon, and the other decentralized social apps. Perhaps they can challenge Big Tech’s dominance of social media, or at least change people’s understanding of what a social network can be.
In a follow-up issue, we’ll look deeper into the engineering culture at Bluesky: the company culture, a deeper look at the tech stack, and how they are building seemingly so much with a surprisingly small team and company. I suspect we can all learn a lot in how a dozen engineers help a startup scale to more than 5 million users.
Enjoyed this issue? Subscribe to get this newsletter every week 👇
 | A guest post by
|