
Real-world engineering challenges: building Cursor
Cursor has grown 100x in load in just a year, sees 1M+ QPS for its data layer, and serves billions of code completions, daily. A deepdive into how it’s built with cofounder, Sualeh Asif

Cursor is an AI-powered IDE which seems the most loved among engineers. In a survey we ran last year, Cursor was the most common answer to the question “what is your favorite editor with GenAI features that help with your work?”.
Anysphere is the startup behind Cursor, founded in 2022, with the first version of Cursor released two years ago, in March 2023. Last week, Anysphere shared they’d raised a $900M Series C round, which values the company at $9.9B(!). The business has crossed $500M in annual revenue(!!) which might be a record: no other dev tools company I know of hit this milestone within 2 years of launching its first product. It helps that Cursor is used by more than half of the 500 largest tech companies on the Fortune 500.
Also last week, the company launched Cursor 1.0, a major release: notable additions are AI code review (with a tool called BugBot), background agents, and support for memory (remembering details from past chats).
I sat down with Cursor cofounder, Sualeh Asif, to find out how Cursor works, and how the team builds the tool, and he shared new details of its internals:
Tech stack. TypeScript and Rust, cloud providers, turbopuffer, Datadog, PagerDuty, and others.
How the autocomplete works. A low-latency sync engine passes encrypted context to the server, which runs inference.
How the Chat works without storing code on the server. Clever use of Merkle trees to avoid storing source code on the server, while being able to search source code using embeddings.
Anyrun: Cursor’s orchestrator service. A Rust service takes care of launching agents in the cloud, securely and with the right process isolation, using Amazon EC2 and AWS Firecracker.
Engineering challenges. Usage patterns dictate technology choices, scaling problems, the cold start problem, sharding challenges, and hard-to-spot outages.
Database migrations out of necessity. How and why Cursor moved from Yugabyte (a database that should scale infinitely), to PostgresSQL. Also, the epic effort of moving to turbopuffer in hours, during a large indexing outage.
Engineering culture and processes. Releases every 2-4 weeks, unusually conservative feature flagging, a dedicated infra team, an experimentation culture, and an interesting engineering challenge they face.
This episode is part of the Real-world engineering challenges series. Read other, similar deepdives.
Cursor by the numbers
Before we jump into the tech stack, let’s start with some context on Cursor in numbers:
50: number of engineers working on Cursor
1M transactions per second, and higher at its peak
100x: growth in users and load in 12 months – doubling month-on-month at times.
100M+: lines of enterprise code written per day with Cursor by enterprise clients, such as NVIDIA, Uber, Stripe, Instacart, Shopify, Ramp, Datadog, and others. Cursor claims more than 50% of the 1,000 largest US companies use its products.
$500M+: annual revenue run rate. This was at $300M in early May, and $100M in January, after being zero a year prior. Could Cursor be setting a revenue growth record?
A billion: just fewer than this many lines of code are written with Cursor daily by enterprise and non-enterprise users
Hundreds of terabytes: scale of indexes stored in Cursor’s databases. This might seem less impressive than the other figures, but code itself is pretty small in terms of storage, compared to images and video. Also, this is not code itself, but embeddings, as Cursor doesn’t store code in its databases.
Cursor may be catching up with GitHub Copilot in revenue generation: Reuters reports GitHub Copilot likely generated $500M in revenue in 2024. Currently, Cursor is on track to generate the same in 2025, or even more if growth continues at the current pace.
1. Tech stack
Some stats about the barely-3-years-old codebase behind Cursor:
25,000 files
7 million lines of code
The editor is a fork of Visual Studio Code, meaning it has the same tech stack as VS Code:
TypeScript: most business logic written in this language
Electron: the framework used by Cursor
When starting the company, they had to decide where to build their editor from scratch, similar to what Zed did, or to start with a fork. Sualeh explains the decision:
“We needed to own our editor and could not ‘just’ be an extension, because we wanted to change the way people program. This meant we either needed to build a brand new IDE, or fork an existing editor.
We decided to fork because starting from scratch would have taken a massive effort just to build a stable editor. Our value proposition was not building a stable editor, but changing how devs program, doing it in an incremental way. For example, building the magical ‘tab model’ would have been very difficult without forking, and it was trivial with the fork. Forking let us focus on the experience, not the editor.”
Backend:
TypeScript: most business logic written in this.
Rust: all performance-critical components use this language. The Orchestrator, discussed below, is an example.
Node API to Rust: Most business logic is in TypeScript and the performance-intensive parts are in Rust, so there’s a bridge to invoke the Rust code from TypeScript, via Node.js. One example is invoking the indexing logic (written in Rust) that makes heavy use of this bridge.
Monolith: the backend service is mostly a large monolith, and is deployed as one. This is a reminder that monoliths work pretty well for early-stage startups and can help teams move fast.
Databases:
turbopuffer: a multi-tenant database used to store encrypted files and the Merkle Tree of workspace, covered below. The team prefers this database for its scalability, and not having to deal with the complexity of database sharding, like previously. We cover challenges in “Engineering challenges”, below.
Pinecone: a vector database storing some embeddings for documentation
Data streaming:
Warpstream: an Apache Kafka compatible data streaming service
Tooling:
Datadog: for logging and monitoring. Sualeh says they’re heavy users and find the developer experience of Datadog vastly superior to the alternatives
PagerDuty: for oncall management, integrated with their Slack
Slack: internal comms and chat
Sentry: error monitoring
Amplitude: analytics
Stripe: billing and payments when purchasing a plan with Cursor.
WorkOS: authentication when logging into Cursor, such as logging in with GitHub or Google Workspace
Vercel: the platform that the Cusor.com website is hosted on
Linear: for managing work
Cursor - naturally! The team uses Cursor to build Cursor. In the end, every engineer is responsible for their own checked-in code, whether they wrote it by hand, or had Cursor generate it.
Model training: Cursor uses several providers to train its own models and finetune existing ones:
Physical infrastructure
All the infrastructure runs on cloud providers. Sualeh says:
“We are very much a ‘cloud shop.’ We mostly rely on AWS and then Azure for inference. We also use several other, newer GPU clouds as well.”
Most of the CPU infra runs on AWS. They also operate tens of thousands of NVIDIA H100 GPUs. A good part of GPUs run within Azure.

Inference is by far the biggest GPU use case for Cursor, which means generating the next tokens, either as autocomplete, or complete code blocks. In fact, Azure GPUs are solely for inference, not other LLM-related work like fine-tuning and training models.
Terraform is what Cursor uses to manage infrastructure such as GPUs and virtual machines, like EC2 instances.
2. How Cursor’s autocomplete works
To understand some of the technical challenges of building Cursor, let’s see what happens when booting up the editor for the first time.
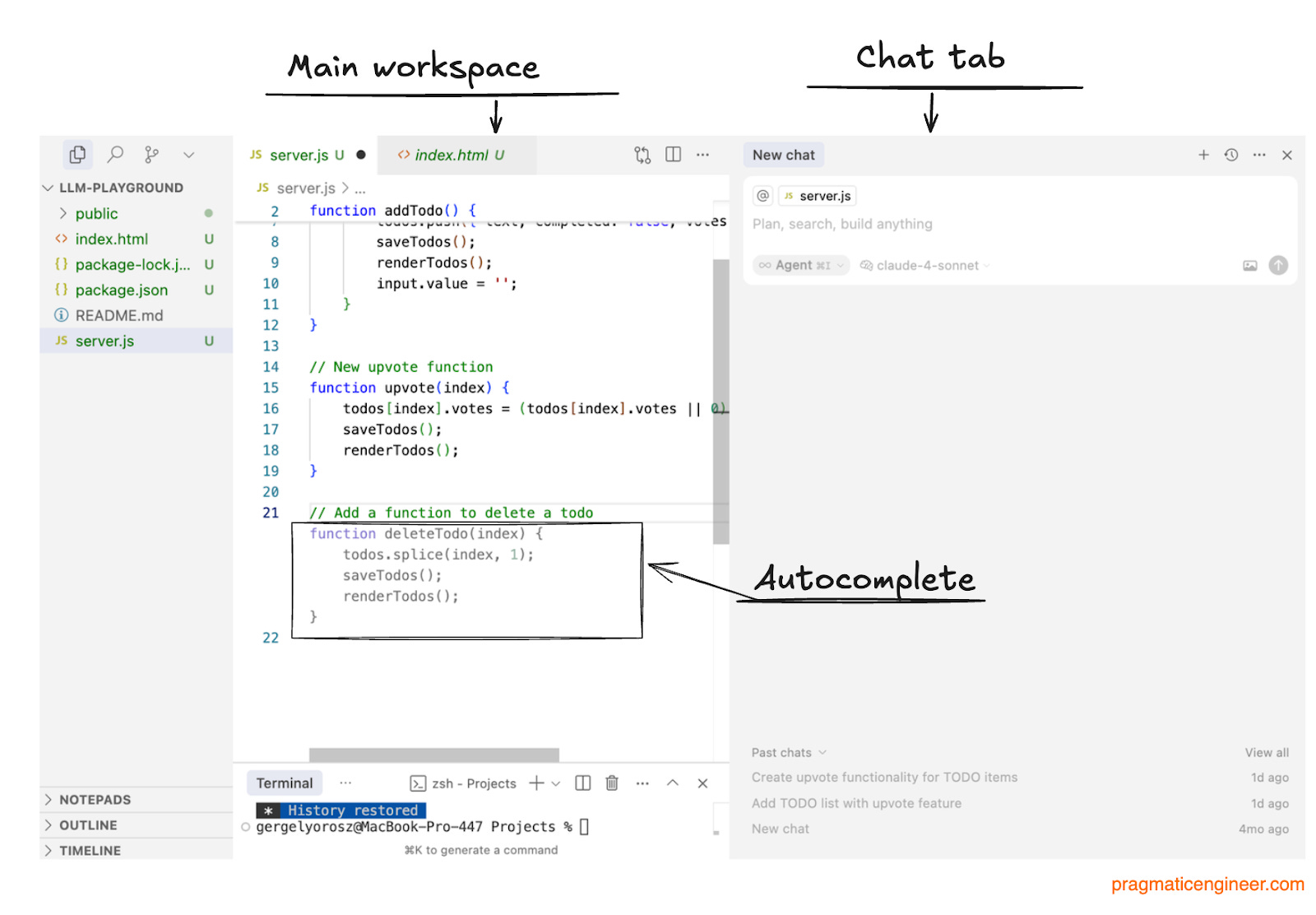
Low-latency sync engine: autocomplete suggestions
Upon opening a project or folder, you’re likely to jump into editing files. This means Cursor needs to generate autocomplete suggestions, which the Cursor team calls tab suggestions.
A low-latency sync engine powers the “tab model”. This generates suggestions that are greyed out and can be accepted by hitting the “Tab” key. The suggestions need to be generated quickly in ideally less than a second. Here’s what happens behind the scenes:

How it works:
A small part of the current context window (code) is collected locally by the client
The code is encrypted
The encrypted code / context is sent to the backend
The backend decrypts the code / context
A suggestion is generated using Cursor’s in-house LLM model
The suggestion is sent back
The IDE displays the suggestion. Hitting “Tab” accepts the suggestion
…the process repeats for the next suggestion.
This “tab model” must be as fast as possible, and data transfer as low as possible. There’s always a tradeoff between how much context to send, and the quality of the suggestions: the more relevant context Cursor can send, the better the suggestions. However, sending lots of context can slow down the display of suggestions, so getting this right is one challenge for Cursor’s engineers.
3. How Cursor’s Chat works without storing code on the server
Cursor supports a chat mode for asking about the codebase, “chatting” with the codebase, or asking Cursor to do things that will kick off an agent to refactor, add some functionality, modify a method, etc. No source code is stored on the backend, but all LLM operations are done there. The way it manages this is through indexes of the codebase. Here’s how it works:
Asking a question in Chat mode: let’s take the example of asking about the createTodo() method, which is part of the codebase, defined in server.js. To complicate things, I defined a similar method called addTodo() in index.html, inline. Let’s see how Cursor gets on with this one!

The prompt is sent to the Cursor server, where it interprets it, and decides it needs to execute a codebase search:

The search starts:

Search is done using codebase indexes. Codebase indexes are previously-created embeddings. It tries to locate the embeddings that are best matches for the context using vector search. In this case, the vector search returned two very close results: in server.js, and index.html.
Requesting the code from the client: the server does not store any source code, but now requests the source code both from server.js and index.html, so it can analyze both and decide which is relevant:

Finally, after the vector search and requesting relevant source code from the client, the server has the context it needs to answer the question:

There’s a few things Cursor does behind the scenes to make these kinds of searches work.
Semantic indexing code with code chunks
To allow vector search using embeddings like in the above case, Cursor first needs to break up the code into smaller chunks, create embeddings, and store these embeddings on the server. Here’s how it does this:

Create code chunks. Cursor slices and dices the contents of a file into smaller parts. Each part will be an embedding later.
Create embeddings without storing filenames or code. Cursor doesn’t even want to store the filenames on the server because it can be considered confidential information. Instead, it sends over obfuscated filenames and encrypted code chunks to the server. The server decrypts the code, creates an embedding using OpenAI’s embedding models, or one of their own, and stores the embedding in their vector database, turbopuffer.
Creating embeddings is computationally expensive and is one reason it’s done on Cursor’s backend, using GPUs in the cloud. Indexing usually takes less than a minute for mid-sized codebases, and can take minutes or longer for large codebases. You can view the status of indexing inside Cursor, at Cursor Settings → Indexing:
Keeping the index up-to-date using Merkle trees
As you edit the codebase with Cursor or another IDE, Cursor’s on-server index becomes out of date. A naive solution would be to run the reindexing operation every few minutes. However, because indexing is expensive in compute – and uses bandwidth by transmitting encrypted code chunks – this is not ideal. Instead, Cursor makes clever use of Merkle trees and a high-latency sync engine (the sync engine runs every 3 minutes) to keep on-server indexes up to date.
A Merkle tree is a tree whose every leaf is the cryptographic hash of the underlying file (e.g. the hash for the file main.js). And every node is a combination of the hashes of its children. A Merkle tree of a simple project with four files looks like this:

How this Merkle Tree works:
Every file gets a hash, based on its contents. The leaves of the tree are files.
Every folder gets a hash, based on the hash of its children.
Cursor uses a very similar Merkle tree to this, except it uses obfuscated file names. The Cursor client creates a Merkle tree based on local files, and the server also creates one based on the files it has finished indexing. This means both the client and server store their respective Merkle trees.
Every 3 minutes, Cursor does an index sync. To determine which files need re-indexing, it compares the two Merkle trees; the one on the client which is the source of truth, and the one on the server which is the state of the index. Let’s take the example of “index.html” changing on the client-side:

Tree traversal is used to locate where re-indexing is needed. Tree traversal is not something us developers implement much, but for this use case, Cursor engineers had to. The Merkle Tree makes tree traversal efficient because starting from the root node, it’s easy enough to tell if the hashes match. Where there are differences in the hashes, it’s also easy enough to find files that need to be synced. Just as importantly, the Merkle tree minimizes sync operations to only files that have changed.
This Merkle tree structure fits nicely into Cursor’s real-world usage. For example, it’s common enough to shut down your computer at the end of the day, and then start the next day by fetching updates from the git repo. In a team, it’s common enough for a bunch of files to change by the next morning. With this Merkle tree, Cursor does as little re-indexing as possible, saving time on the client side and using compute as efficiently as possible on its server side.
Secure indexing
Even though Cursor doesn’t store code on the server-side, there are sensitive parts of a codebase that are a bad idea to send over, even when encrypted. Sensitive data includes secrets, API keys, and passwords.
Using .gitignore and .cursorignore is the best way to keep indexing secure. Secrets, API keys, passwords, and other sensitive information, should not be uploaded to source control, and are usually stored as local variables, or in local environment files (.env files) that are added to the .gitgnore. Cursor respects .gitignore and will not index files listed there, nor will it send contents of those files to the server. Additionally, it offers a .cursorignore file where files to be ignored by Cursor should be added.
Before uploading chunks for indexing, Cursor also scans code chunks for possible secrets or sensitive data, and does not send them.
Indexing very large codebases
For massive codebases – often monorepos with tens of millions of lines of code – indexing the whole codebase is extremely time consuming, uses a lot of Cursor’s compute resources, and is generally unnecessary. Using the .cursorignore file is the sensible approach at this point. The documentation offers more guidance.
4. Anyrun: Cursor’s orchestrator service
Anyrun is the name of Cursor’s orchestrator component, and is written fully in Rust. Fun fact: “Anyrun” is a nod to Cursor’s company name, Anysphere. Anyrun is responsible for this: