
Cursor makes developers less effective?
A study into the workflows of experienced developers found that devs who use Cursor for bugfixes are around 19% slower than devs who use no AI tools at all.

An interesting study has been published by the nonprofit org, Model Evaluation and Threat Research (METR). They recruited 16 experienced developers who worked on large open source repositories, to fix 136 real issues, for pay of $150/hour. Some devs were assigned AI tools to use, and others were not. The study recorded devs’ screens, and then examined and analyzed 146 hours of footage. The takeaway:
“Surprisingly, we find that when developers use AI tools, they take 19% longer than without. AI makes them slower. (...) This gap between perception and reality is striking: developers expected AI to speed them up by 24%, and even after experiencing the slowdown, they still believed AI had sped them up by 20%.”
This result is very surprising! But what is going on? Looking closely at the research paper:
The research is about Cursor’s impact on developer productivity. The AI tool of choice for pretty much all participants was Cursor, using Sonnet 3.5 or 3.7. A total of 44% of developers had never used Cursor before, and most others had used it for up to 50 hours.
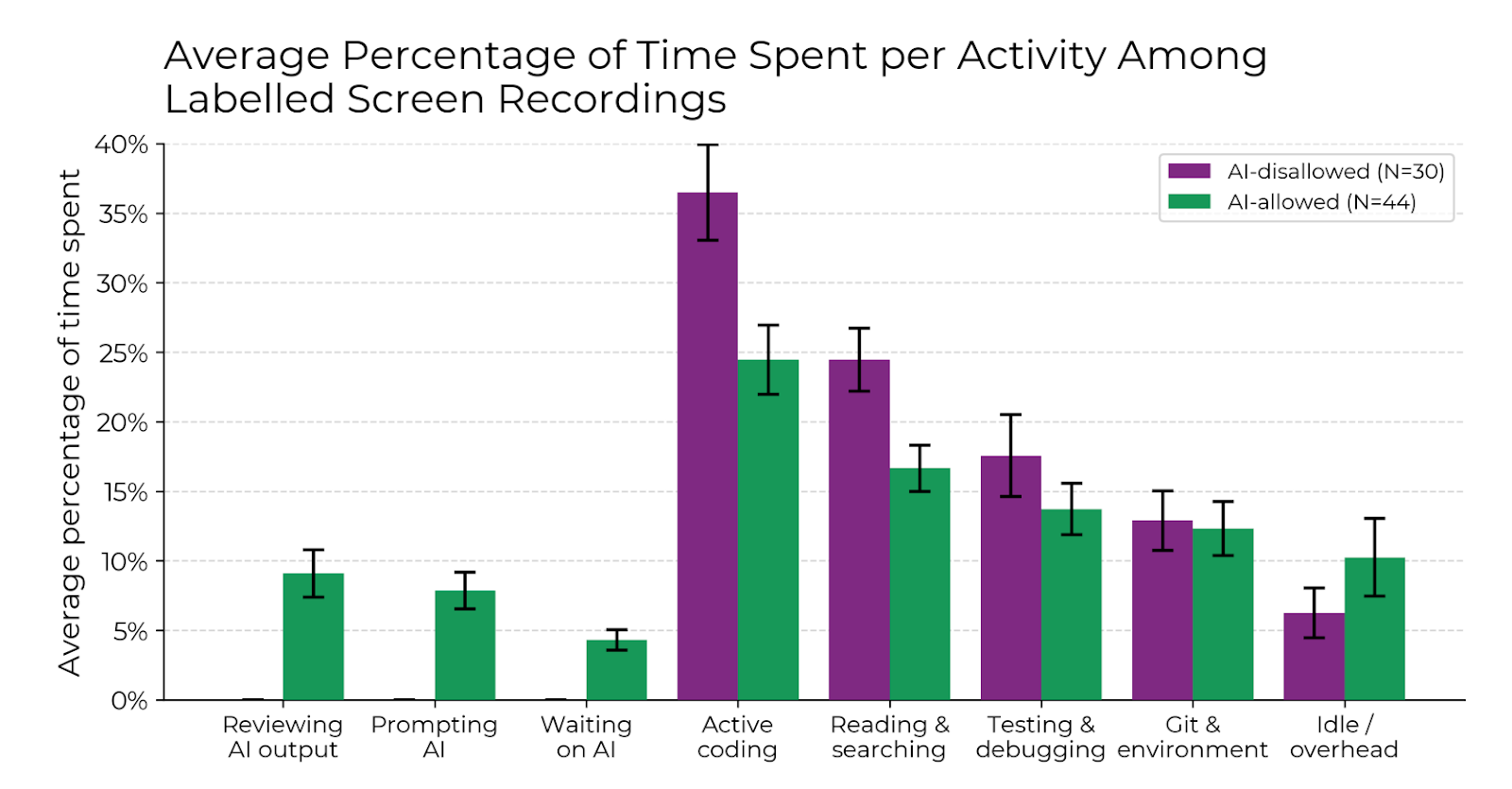
Those using AI spent less time on coding to complete the work – but took more time, overall. They also spent less time on researching and testing. But they took longer on promoting, waiting on the AI, reviewing its output, and on “IDE overhead”, than those not using AI. In the end, additional time spent with the AI wiped out the time it saved on coding, research, and testing, the study found.
It’s worth pointing out that this finding applies to all AI tools, and not only to Cursor, which just happens to be the tool chosen for this study.
Developers are over optimistic in their estimates about AI’s productivity impact – initially, at least. From the survey:
“Both experts and developers drastically overestimate the usefulness of AI on developer productivity, even after they have spent many hours using the tools. This underscores the importance of conducting field experiments with robust outcome measures, compared to relying solely on expert forecasts or developer surveys.”
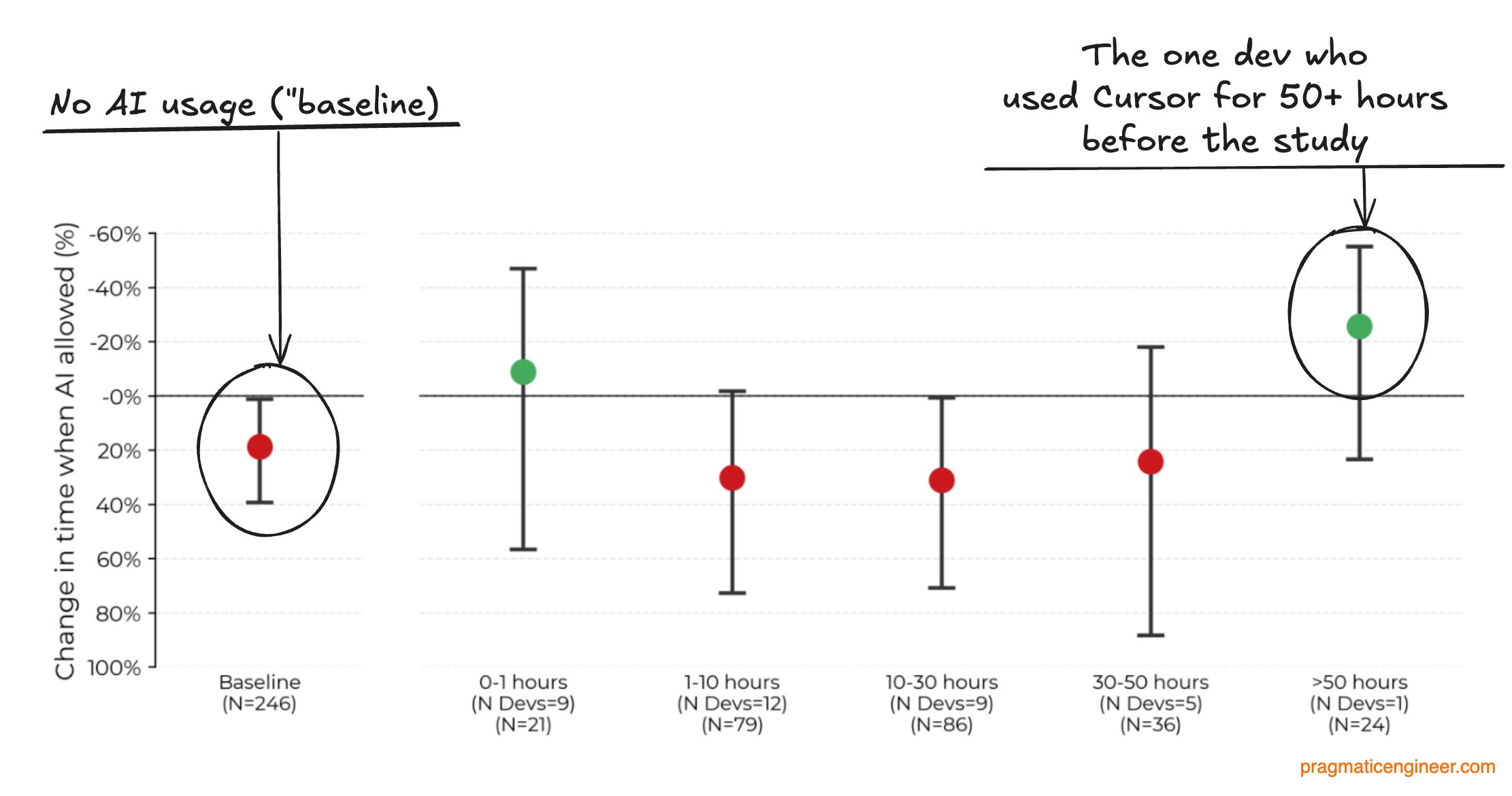
The one dev who had used Cursor for 50+ hours saw a lot of speedup! In the study, there was a single developer who had used Cursor for a total of more than 50 hours, previously. This dev saw a very impressive 38% increase in speed. Then again, a sample size of one is not very representative of a group of 16:
Software engineer Simon Willison – whom I consider an unbiased expert on AI dev tools – interprets the survey like this:
“My intuition here is that this study mainly demonstrated that the learning curve of AI-assisted development is high enough that asking developers to bake it into their existing workflows reduces their performance while they climb that learning curve.”
Indeed, he made a similar point on an episode of the Pragmatic Engineer podcast: “you have to put in so much effort to learn, to explore and experiment, and learn how to use it. And there's no guidance.”
In research on AI tools by this publication, based on input from circa 200 software engineers, we found supporting evidence of that: those who hadn’t used AI tools for longer than 6 months were more likely to have a negative perception of them. Very common feedback from engineers who didn’t use AI tooling was that they’d tried it, but it didn’t meet expectations, so they stopped.
The engineer who saw a 38% “speed-up” versus non-AI devs has an interesting take. That lone engineer with 50+ hours of Cursor experience is PhD student, Quentin Anthony. Here’s what he says about the study, and how AI tools impact developer efficiency:
“1. AI speedup is very weakly correlated to anyone's ability as a dev. All the devs in this study are very good. I think it has more to do with falling into failure modes, both in the LLM's ability and the human's workflow. I work with a ton of amazing pretraining devs, and I think people face many of the same problems.
We like to say that LLMs are tools, but treat them more like a magic bullet.
Literally any dev can attest to the satisfaction of finally debugging a thorny issue. LLMs are a big dopamine shortcut button that may one-shot your problem. Do you keep pressing the button that has a 1% chance of fixing everything? It's a lot more enjoyable than the grueling alternative, at least to me.
2. LLMs today have super spiky capability distributions. I think this has more to do with:
what coding tasks we have lots of clean data for
what benchmarks/evals LLM labs are using to measure success.
As an example, LLMs are all horrible at low-level systems code (GPU kernels, parallelism/communication, etc). This is because their code data is relatively rare, and evaluating model capabilities is hard (I discuss this in more detail here).
Since these tasks are a large part of what I do as a pretraining dev, I know what parts of my work are amenable to LLMs (writing tests, understanding unfamiliar code, etc) and which are not (writing kernels, understanding communication synchronization semantics, etc). I only use LLMs when I know they can reliably handle the task.
When determining whether some new task is amenable to an LLM, I try to aggressively time-box my time working with the LLM so that I don't go down a rabbit hole. Again, tearing yourself away from an LLM when "it's just so close!" is hard!
3. It's super easy to get distracted in the downtime while LLMs are generating. The social media attention economy is brutal, and I think people spend 30 mins scrolling while "waiting" for their 30-second generation.
All I can say on this one is that we should know our own pitfalls and try to fill LLM-generation time productively:
If the task requires high-focus, spend this time either working on a subtask, or thinking about follow-up questions. Even if the model one-shots my question, what else don't I understand?
If the task requires low-focus, do another small task in the meantime (respond to email/slack, read or edit another paragraph, etc).
As always, small digital hygiene steps help with this (website blockers, phone on dnd, etc). Sorry to be a grampy, but it works for me :)”
Quentin concludes:
“LLMs are a tool, and we need to start learning its pitfalls and have some self-awareness. A big reason people enjoy Andrej Karpathy's talks is because he's a highly introspective LLM user, which he arrived at a bit early due to his involvement in pretraining some of them.
If we expect to use this new tool well, we need to understand its (and our own!) shortcomings and adapt to them.”
I wonder if context switching could become the Achilles Heel of AI coding tools. As a dev, the most productive work I do is when I’m in “the zone”, just locked into a problem with no distractions, and when my sole focus is work! I know how expensive it is to get back into the zone after you fall out of it.
But I cannot stay in the zone when using a time-saving AI coding tool; I need to do something else while code is being generated, so context switches are forced, and each one slows me down. It’s a distraction.
What if the constraint of being “in the zone” when writing code is a feature, not a bug? And what if experienced devs not using AI tools outperform most others with AI because they consciously stay in “the zone” and focus more? Could those without AI tools have been “in the zone” and working at a higher performance level than devs forced into repeated context switches by their AI tools?
There’s food for thought here about how time saved on coding doesn’t automatically translate into higher productivity when building software.
This was one out of four topics from last week's The Pulse. The full issue also covers:
Industry pulse. Why 1.1.1.1 went down for an hour, Microsoft cut jobs to buy more GPUs, Meta’s incredible AI data center spend, and the “industry-wide problem” of fake job candidates from North Korea.
Windsurf sale: a complicated story of OpenAI, Microsoft, Google, and Cognition. OpenAI wanted to buy Windsurf but couldn’t because of Microsoft. Google then hired the founders and core team of Windsurf, and Cognition (the maker of Devin) bought the rest of the company. It’s a weird story that could not happen outside of California – thanks to California having a ban on noncompetes.
Beginning of the end for VC-subsidized tokens? Cursor angered devs by silently imposing limits on its “unlimited” tier. Us devs face the reality that LLM usage is getting more expensive – and VC funding will probably stop subsidizing the real cost of tokens.
This week's The Pulse issue – sent out to full subscribers – covers:
Mystery solved about the cause of June 10th outages. Heroku went down for a day due to an update to the systemd process on Ubuntu Linux. Turns out that dozens of other companies including OpenAI, Zapier, and GitLab, were also hit by the same issue, with outages of up to 6 hours.
Replit AI secretly deletes prod – oops! Cautionary tale of why vibe-coding apps are not yet production-ready, which makes it hard to foresee production-hardened apps being shipped with no software engineering expertise involved.
Industry pulse. Fresh details about the Windsurf sale, Zed editor allows all AI functionality to be turned off, government agencies using Microsoft Sharepoint hacked, GitHub releases vibe coding tool, and more.
Reflections on a year at OpenAI. Software engineer Calvin French-Owen summarized his impressions of OpenAI, sharing how the company runs on Slack and Azure, capacity planning challenges for OpenAI Codex launch, learnings from working on a large Python codebase, and more.