
Inside Google’s Engineering Culture: the Tech Stack (Part 2)
Deepdive into how Google works from SWEs’ perspectives at the Tech Giant: planet-scale infra, tech stack, internal tools, and more


“What’s it really like, working at Google?” is the question this mini series looks into. To get the details, we’ve talked with 25 current and former software engineers and engineering leaders between levels 4 and 8. We also spent the past year researching: crawling through papers and books discussing these systems. The process amassed a wealth of information and anecdotes that are combined in this article (and mini-series). We hope it adds up to an unmatched trove of detail compared to what’s currently available online.
In Part 1, we already covered:
An overview of Google
What makes Google special?
Levels and roles
Compensation
Hiring
Today, we dig into the tech stack because one element that undoubtedly makes the company stand out in the industry is that Google is a tech island with its own custom engineering stack.
We cover:
Planet-scale infra. Google’s internal infrastructure was built for ‘planet-scale’ by default, but Google Cloud does not support this out of the box; hence, most engineering teams build on Google’s PROD stack, not GCP.
Monorepo. Also known as “Google3,” 95% of all Google’s code is stored in one giant repository that has billions of lines. Trunk-based development is the norm. Also, the monorepo doesn’t mean Google has a monolithic codebase.
Tech stack. C++, Kotlin, Java, Python, Go, and TypeScript are officially supported, with heavy use of Protobuf and Stubby. Google has language style guides for most languages that are almost always enforced.
Dev tooling. A different dev tool stack from any other workplace. Goodbye GitHub, Jenkins, VS Code, and other well-known tools: hello Piper, Fig, Critique, Blaze, Cider, Tricorder, Rosie, and more.
Compute and storage. Borg, Omega, Kubernetes, BNS, Borgmon, Monarch, Viceroy, Analog, Sigma, BigQuery, Bigtable, Spanner, Vitess, Dremel, F1, Mesa, GTape, and many other custom systems Google runs on. This infra stack is unlike anywhere else’s.
AI. Gemini is integrated inside developer tools and most internal tools – and Google is heavily incentivizing teams to build AI whenever possible. Teams can request GPU resources for fine tuning models, and there’s a pile of internal GenAI projects.
1. Planet-scale infra
Google’s infrastructure is distinct from every other tech company because it’s all completely custom: not just the infra, but also the dev tools. Google is a tech island, and engineers joining the tech giant can forget about tools they’re used to – GitHub, VS Code, Kubernetes, etc. Instead, it’s necessary to use Google’s own version of the tool when there’s an equivalent one.
Planet-scale vs GCP
Internally, Google engineers say “planet scale” as the company’s capacity to serve every human on Earth. All its tooling operates at global scale. That’s in stark contrast to Google Cloud Platform (GCP), with no such “planet-scale” deployment options built in – it’s possible to build applications that can scale that big, but it would be a lot of extra work. Large GCP customers which managed to scale GCP infrastructure to planetary proportions include Snap, which uses GCP and AWS as their cloud backend, and Uber that uses GCP and Oracle, as detailed in Inside Uber’s move to the cloud.
Google doesn’t only run the “big stuff” like Search and YouTube on planet-scale infrastructure; lots of greenfield projects are built and deployed on this stack, called PROD.
As an aside, the roots of database Planetscale (the database Cursor currently runs on) run to Google, and its “planet-scale” systems. Before co-founding Planetscale, Sugu Sougoumarane worked at Google on YouTube, where he created Vitess, an open source database to scale MySQL. Sugu now works on Multigres, an adaptation of Vitess for Postgres. I asked where the name Planetscale comes from. He said:
“The first time I heard the term ‘planet-scale’ was at Google. I chuckled a bit when I heard it because it’s not possible to build a globally-distributed ACID database without trade-offs. But then, Vitess was already running at “planet-scale” at YouTube, with data centers in every part of the world.
So, when we decided to name PlanetScale; it was a bold claim, but we knew Vitess could uphold it.”
Planetscale originally launched with a cloud-hosted instance of Vitess and gained popularity thanks to its ability to support large-scale databases. It’s interesting to see Google’s ‘planet-scale’ ambition injected into a database startup, co-founded by a Google alumnus!
PROD stack
“PROD” is the name for Google’s internal tech stack, and by default, everything is built on PROD: both greenfield and existing projects. There are a few exceptions for things built on GCP; but being on PROD is the norm.
Some Googlers say PROD should not be the default, according to a current Staff software engineer. They told us:
“A common rant that I hear from many Googlers – and a belief I also share – is that very few services need to actually be ‘planet-scale’ on day 1! But the complexity of building a planet-scale service even on top of PROD, actually hurts productivity and go-to-market time for new projects.
Launching a new service takes days, if not weeks. If we used a simpler stack, the setup would take seconds, and that’s how long it ought to take for new projects that might not ever need to scale! Once a project gets traction, there should be enough time to add planet-scale support or move over to infra that supports this.”
Building on GCP can be painful for internal-facing products. A software engineer gave us an example:
“There are a few examples of internal versions of products built on GCP that did have very different features or experiences.
For example, the internal version of GCP’s Pub/Sub is called GOOPS (Google Pub/Sub). To configure GOOPS, you could not use the nice GCP UI: you needed to use a config file. Basically, external customers of GCP Pub/Sub have a much better developer experience than internal users.”
It makes no sense to use a public GCP service when there’s one already on PROD. Another Google engineer told us the internal version of Spanner (a distributed database) is much easier to set up and monitor. The internal tool to manage Spanner is called Spanbob, and there’s also an internal, enhanced version of SpanQSL.
Google released Spanner on GCP as a public-facing service. But if any internal Google team used the GCP Spanner, they could not use Spanbob – and have to do a lot more work just to set up the service! – and could not use the internal, enhanced SpannerSQL. So, it’s understandable that virtually all Google teams choose tools from the PROD stack, not the GCP one.
The only Big Tech not using its own cloud for new products
Google is in a position where none of its “core” products run GCP infrastructure: not Search, not YouTube, not Gmail, not Google Docs, nor Google Calendar. New projects are built on PROD by default, not GCP.
Contrast this with Amazon and Microsoft, which do the opposite:
Amazon: almost fully on AWS, and everything new is built on it. Almost all services have moved over to AWS. The “modern stack” is NAWS (Native AWS) and all new projects use it. The rest of the stack is MAWS (Move to AWS); legacy systems yet to move to AWS.
Microsoft: heavy use of Azure, with everything new built on it. Microsoft 365, Microsoft Teams, Xbox Live, and GitHub Actions and Copilot operate on top of Azure. Acquisitions like LinkedIn and GitHub are gradually moving to Azure, on which every new project is built by default.
Why do Google’s engineering teams resist GCP?
No “planet-scale” support out of the box. A common reason to start with PROD is that it means if the product or service surges in popularity, it can grow infinitely without an infrastructure migration.
Superior developer experience with PROD. Spanner is an obvious case; in general, tools built on PROD are much better and easier to work for Google devs.
Historic aversion to GCP. 5-10 years ago it was hard to make a case to build anything on GCP. Back then, it was missing several internal systems that were must-haves for internal projects, such as auditing and access controls iterating with internal systems. These days, this has changed but the aversion to GCP hasn’t.
A current Google software engineer summed it up:
“The internal infra is world class and probably the best in the industry. I do think more Google engineers would love to use GCP but the internal infra is purpose-built whereas GCP is more generic to target a wider audience”.
Another software engineer at the company said:
“In the end, PROD is just so good that GCP is a step down in comparison. This is the case for:
Security – comes out of the box. GCP needs additional considerations and work
Performance – it’s easy to get good performance out of the internal stack
Simplicity – trivial to integrate internally, whereas GCP is much more work
A big reason to use GCP is for dogfooding, but doing so comes with a lot of downsides, so teams looking for the best tool just use PROD”.
The absence of a top-down mandate is likely another reason. Moving over from your own infra to use the company’s cloud is hard! When I worked at Skype as part of Microsoft in 2012, we were given a top-down directive to move Skype fully over to Azure. The Skype Data team did that work, who were next to me, and it was a grueling, difficult process because Azure just didn’t have good-enough support or reliability at the time. But as it was a top-down order, it eventually happened anyway! The Azure team prioritized the needs of Skype and made necessary improvements, and the Skype team made compromises. Without pressure from above, the move would have never happened, since Skype had a laundry list of reasons why Azure was suboptimal as infrastructure, compared to the status quo.
Google truly is a unique company with internal infrastructure that engineers consider much better than its public cloud, GCP. Perhaps this approach also explains why GCP is the #3 cloud provider, and doesn’t show many signs of catching AWS and Azure. After all, Google is not giving its own cloud the vote of confidence – never mind a top-down adoption mandate! – as Amazon and Microsoft did with theirs.
2. Monorepo
Google stores all code in one repository called the monorepo – also referred to as “Google3”. The size of the repo is staggering – here are stats from 2016:
2+ billion lines of code
1 million files
9 million source files
45,000 commits per day
15,000 by software engineers
30,000 by automated systems
95% of engineers at Google use the monorepo
800,000 QPS: read requests to the repository at peak, with 500,000 reads/second on average each workday. Most traffic comes not from engineers, but from Google’s automated build-and-test systems.
Today, the scale of Google’s monorepo has surely increased several times over.
The monorepo stores most source code. Notable exceptions are open-sourced projects:
Android: Google’s smartphone operating system
Chromium: Google’s open source web browser. Google Chrome, Microsoft’s Edge, Opera, Brave, DuckDuckGo Browser and many others are built on top of Chromium.
Go: the backend programming language created by Google
As a fun fact, these open source projects were hosted for a long time on an internal Git host called “git-on-borg“ for easy internal access (we’ll cover more on Borg in the Compute and Storage section.) This internal repo was then mirrored externally.
Trunk-based development is the norm. All engineers work in the same main branch, and this branch is the source of truth (the “trunk”). Devs create short-lived branches to make a change, then merge back to trunk. Google’s engineering team has found that the practice of having long-lived development branches harms engineering productivity. The book Software Engineering at Google explains:
“When we include the idea of pending work as akin to a dev branch, this further reinforces that work should be done in small increments against trunk, committed regularly.”
In 2016, Google already had more than 1,000 engineering teams working in the monorepo, and only a handful used long-lived development branches. In all cases, using a long-lived branch boiled down to having unusual requirements, with supporting multiple API versions a common reason.
Google’s trunk-based development approach is interesting because it is probably the single largest engineering organization in the world, and it’s important that it has large platform teams to support monorepo tooling and build systems to allow trunk-based development. In the outside world, trunk-based development has become the norm across most startups and scaleups: tools that support stacked diffs are a big help.
Documentation often lives in the monorepo and this can create problems. All public documentation for APIs on Android and Google Cloud are checked into the monorepo, which means documentation files are subject to the same readability rules as Google code. Google has strict readability constraints on all source code files (covered below). However, with external code, the samples don’t usually follow the internal readability guidelines by design!
For this reason, it has become best practice to have code samples outside of the monorepo, in a separate GitHub repository, in order to avoid the readability review (like naming an example file quickstart.java.txt).
For example, here’s an older documentation example where the source code is in a separate GitHub repository file to avoid Google’s readability review. For newer examples like this one, code is written directly into the documentation file which is set up to not trigger a readability review.
Not all of the monorepo is accessible to every engineer. The majority of the codebase is, but some parts are restricted:
The OWNERS file: this file controls the list of the owners of the code. In order to merge anything, you need reviews from at least one engineer in this list. The “OWNERS” model applies to open source projects like Android or Chromium.
Silos for sensitive parts: READ permissions are restricted on sensitive projects, or sensitive parts of them. For example, certain prompts in the Gemini project are only readable to engineers working on it.
Infra considerations for sensitive projects: infrastructure teams need to access even sensitive projects, so they can set up tooling like codemod (for automated tool transformations). Infra teams usually nominate one or two infra maintainers who are added to the global allowlist to see these sensitive projects, and to help with developer tooling setup and issues.
Architecture and systems design
In 2016, Google engineering manager Rachel Potvin explained that despite the monorepo, Google’s codebase was not monolithic. We asked current engineers there if this is still true, and were told there’s been no change:
“I honestly notice very little difference from orgs that use separate repos, like at AWS. In either case, we had tools to search across all code you have permissions for.” – L6 Engineering Manager at Google.
“The software engineering process is distributed, not centralized. The build system is like Bazel (internally, it’s called Blaze). Individual teams can have their own build target(s) that goes through a separate CI/CD.” – L6 Staff SWE at Google.
Another Big Tech that has been using a monorepo since day one is Meta. We covered more on its monorepo in Inside Meta’s engineering culture.
Each team at Google chooses its own approach to system design, which means products are often differently designed! Similarities lie in the infra and dev tooling all systems use, and low-level components like using Protobuf and Stubby, the internal gRPC. Below are a few common themes from talking with 20+ Googlers:
Services are common, everywhere. Google doesn’t really think of them as “microservices” since many are large and complicated. But teams rarely ever target monolithic architectures. When a service gets too big, it’s usually broken into smaller services, mostly for scaling reasons rather than for modularity.
Stubby used for service-to-service comms. It’s the default way services talk to one another; gRPC is rare, and usually only for external services.
A current Google engineer summarized the place from an architectural perspective:
“Google feels like many small cathedrals contained in one large bazaar.”

This metaphor derives from the book The Cathedral and the Bazaar, where the cathedral refers to closed-source development (organized, top-down), and the Bazaar is open-source development (less organized, bottom-up.)
A few interesting details about large Google services:
YouTube used to be a Python monolith, but later was rewritten in C++ and Java. Years ago, every release had a 50-hour manual release testing cycle run by a remote QA team.
Google Search is the largest and most monolithic codebase. It’s the exception not the rule to have monolithic codebases.
Ads and Cloud are using ever more (micro)services.
Rewriting services for microservices is an approach Google uses in some cases. Rewriting an app from scratch as microservices (to establish the right level of modularity) is less effort than breaking up the monolith.
3. Tech stack
Officially-supported programming languages
Internally, Google officially supports the programming languages below – meaning there are dedicated tooling and platform teams for them:
C++
Kotlin and Java
Python
Go
TypeScript and JavaScript
Engineers can use other languages, but they just won’t have dedicated support from developer platform teams.
TypeScript is replacing JavaScript in Google, several engineers told us. The company no longer allows new JavaScript files to be added, but existing ones can be modified.
Kotlin is becoming very popular, not just on mobile, but on the backend. New services are written almost exclusively using Kotlin or Go, and Java feels “deprecated”. The push towards Kotlin from Java is driven by software engineers, most of whom find Kotlin more pleasant to work with.
For mobile, these languages are used:
Objective C and Swift for iOS
Kotlin for Android (and Java for legacy apps). Also, Rust is regularly used for Android.
Dart for Flutter (for cross-platform applications)
Language style guides are a thing at Google and each language has its own style guides. Some examples:
Google Java style – the Google Java format tool formats code to be compatible with this style
Interoperability and remote procedure calls
Protobuf is Google’s approach to interoperability, which is about working across programming languages. Protobuf is short for “Protocol buffers”: a language-neutral way to serialize structured data. Here’s an example protobuf definition:
edition = “2024”;
message Person {
string name = 1;
int32 id = 2;
string email = 3;
}
This can be used to pass the Person object across different programming languages; for example, between a Kotlin app and a C++ one.
An interesting detail about Google’s own APIs, whether it’s GRPC, Stubby, REST, etc, is that they are all defined using protobuf. This definition then generates API clients for all languages. And so internally, it’s easy to use these clients and call the API without worrying about underlying protocol.
gRPC is a modern, open source, high-performance remote procedural call (RPC) framework to communicate between services. Google open sourced and popularized this communication protocol, which is now a popular alternative to REST. The biggest difference between REST and gRPC is that REST uses HTTP for human-readable formatting, while gRPC is a binary format and outperforms REST with smaller payloads and less serialization and deserialization overhead. Internally, Google services tend to communicate using the “Google internal gRPC implementation” called Stubby, and to not use REST.
Stubby is the internal version of gRPC and the precursor to it. Almost all service-to-service communication is via Stubby. In fact, each Google service has a Stubby API to access it. gRPC is only used for external-facing comms, such as making external gRPC calls.
The name “stubby” comes from how protobuffers can have service definition, and that stubs can be generated from those functions from each language. And from “stub” comes “stubby.”
4. Dev tooling
In some ways, Google’s day-to-day tooling for developers most clearly illustrates how different the place is from other businesses:
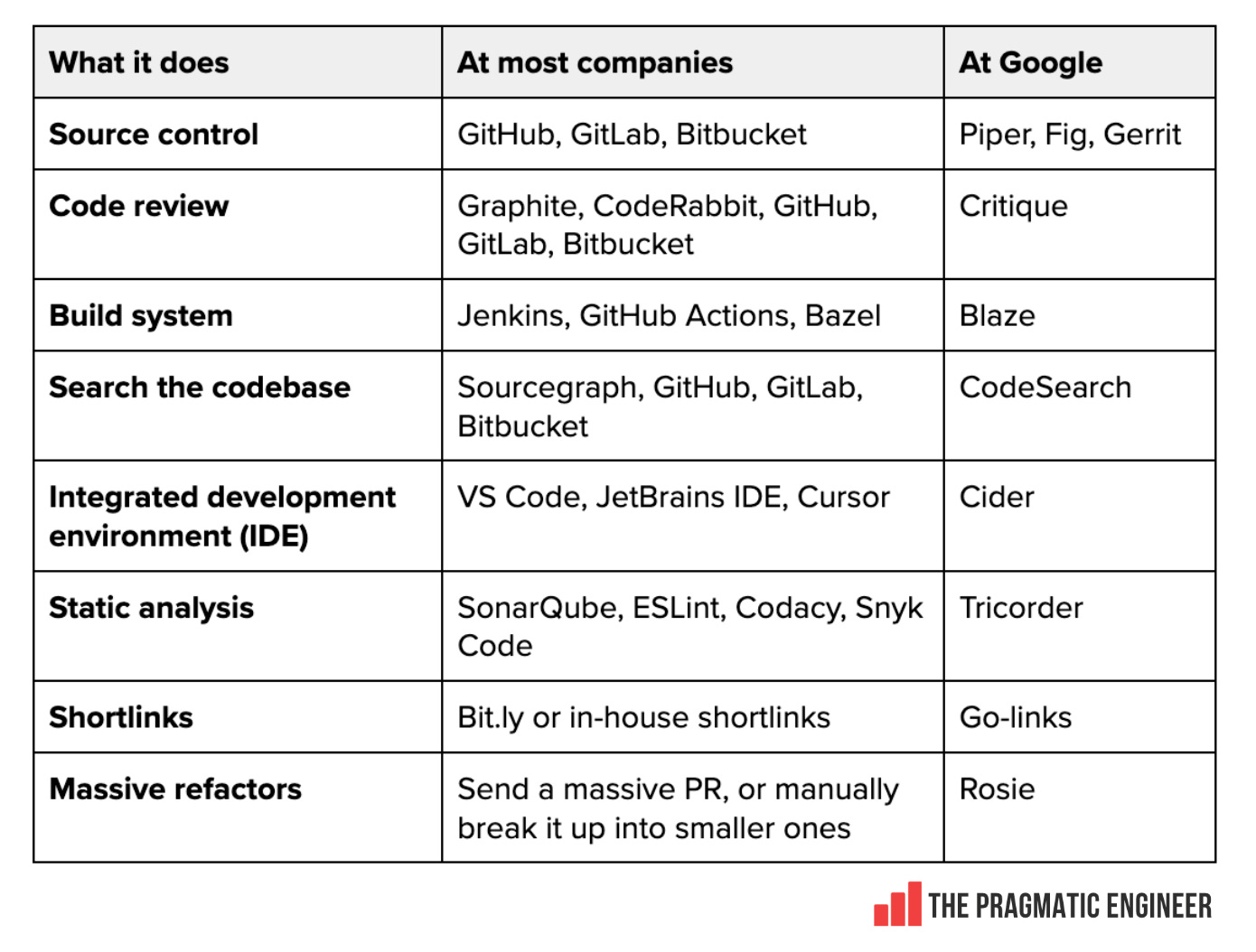
Let’s go through these tools and how they work at the tech giant:
 | A guest post by
|