
Inside Agoda’s Private Cloud: Part 2
The application stack running on the private cloud, Agoda’s cloud strategy, and whether to move to the cloud or stay on-prem.

👋 Hi, this is Gergely with a 🔒 subscriber-only issue 🔒 of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. Subscribe to get issues like this, weekly:
In a previous two-part series, we dived into Uber’s multi-year project to move onto the cloud, away from operating its own data centers. In a different approach, travel booking platform Agoda has decided against onboarding to the cloud – at least for now.
In Part 1 of this 2-part series, we went through the evolution of data centers at Agoda, inspected the hardware the company uses, and took a detailed tour inside their data centers. In this issue, we move onto the software stack, and learnings about operating your own private cloud, with details coming from Agoda’s CTO, Idan Zalzberg
Today, we cover:
The application stack inside the private cloud. Fleet, Buckbeak, Agoda’s detailed data stack and bespoke developer portal.
Agoda’s cloud strategy and usage. Is Agoda’s goal to operate off the cloud, or on it? What are the use cases where the company already utilizes public cloud?
To move or not to move to the cloud. How Agoda knows if it’s time to move away from on-prem servers. Are location-based expenses keeping the company off public clouds?
A surprise advantage for hiring software engineers. Owning their own stack end-to-end comes with unexpected hiring benefits, when attracting developers.
Agoda’s learnings from operating its own DCs. The importance of standardizing, and why to minimize your tech stack.
The cloud or your own data centers? Idan’s advice for any midsize company weighing up on-prem versus public cloud.
1. The application stack inside the private cloud
Agoda uses the name “private cloud” for microservices that comprise the online part of the company, which is all the typical frontend and backend services.
The stack private cloud consists of:
Fleet (running Kubernetes): Agoda’s compute management platform
An Istio layer on top of Fleet. Istio is a platform-independent service mesh providing traffic management, policy enforcement and telemetry collection
Buckbeak: Agoda’s home-grown federated deployment service. Buckbeak handles deployments across multiple clusters, managing clusters that are spread across multiple DCs, deploying to multiple clusters, and allows for canary deployments. Buckbeak is built on top of the delivery platform KubeVela.
Fleet is Agoda’s internal compute management platform. The company’s goal in developing Fleet was to seamlessly manage physical servers, VMs and containers at DC-scale. Fleet handles the entire provisioning process from the server being powered up, until its resources are allocated to a bare-metal, containerized or VM workload.
Fleet leverages approaches like:
Modern kernel features for hardware performance optimization (SR-IOV: single root I/O virtualization)
Network traffic segregation (with approaches like BPF filters)
CPU security enclaves: a set of security-related instruction codes built into newer CPUs which protect applications and data while in use
Agoda built Fleet on top of Kubernetes with a design objective to run workloads in a nested-virtualization environment with minimal performance impact – or a few percentage points of impact, at most. It’s still under active development and the engineering team continues to add new features and capabilities.
Each DC operates a couple of separate clusters for additional resilience. This setup means failures within a cluster can be localized and the cluster can be taken out of user traffic during an investigation. Of course, this approach only applies when the failure is not part of a particular service deployment. The goal is to identify failures quickly, ideally at time of deployment.
In this context, cluster failures refer to failures which are “global” to the cluster level. These could be the cluster infrastructure itself, like upgrading Cilium (communication between containers) and finding out it doesn’t work well with the current version of Istio (the service mesh layer on top of Fleet), thereby impacting service deployments.
All deployments have canaries, though it’s often hard to see the impact of a bad deployment in the metrics alone. However, the ecosystem that the cluster is interacting with might show a drop in business-level metrics. And when the engineering team sees a drop in business metrics, then it’s useful to have multiple clusters as it’s easy to localize a failure event to a cluster – even in business terms. The engineering team can then mitigate this failure quickly by moving traffic away from that cluster while looking into the root cause.
Database layer
Agoda operates a database-as-a-service (DBAAS) layer, which is provided by the DBAAS team. Users can ask for a database and get it in a way that vaguely resembles Amazon’s RDS (a fully managed relational database service.) Agoda provides a much deeper level of support than a cloud provider, thanks to its in-house approach.
All queries in the database are done via stored procedures. The DBAAS team built tooling so that developers can easily develop and test those stored procedures and store them in their git repositories. When developers make a change to a stored procedure, this happens via a pull request, when Agoda’s automated tooling detects there is a change to be made in a stored procedure. Then it:
Tests the change’s performance automatically versus the previous version of the stored procedure
Tests they use indexes properly
If all of these pass, it approves the merge request (MR)
If a change is not simple enough to approve automatically, a database administrator (DBA) is assigned to review it as part of the MR.

Using stored procedures this extensively is not a common choice these days, but it provides Agoda with a perfect isolation layer between the database and the application for the contract, performance, security and change management.
The DBAs can immediately see exactly which stored procedures are causing load to the database, and whether they were introduced recently or not. Here’s an example of what a reviewer or a DBA sees when a regression happens:

Being able to pinpoint regressions gives an advantage in managing databases, beyond just setting a database up like Amazon RDS does. It guarantees the performance and stability for its own developers’ usage.
Agoda shares more details on its CI/CD system in the engineering blog post, Managing 14K database changes across 400 production instances.
The DBAAS team not only applies this approach to MSSQL (relational database,) but provides similar “in-house managed services” for PostgreSQL (relational database,) ScyllaDB (a NoSQL database,) Couchbase (NoSQL database,) Elasticsearch (search and analytics,) RabbitMQ (messaging,) Kafka (messaging.)
For persistent storage, Agoda has a database team who manage around 1,200 server instances of databases across all DCs. Their servers come in a variety of different flavors:
Microsoft SQL Server: most of the databases
PostgresSQL: some of them
Couchbase, Elasticsearch, ScyllaDB: for more specialized use cases
The persistent storage machines operate on bare-metal or on virtual machines running Openstack, so there’s no need for an efficient block-level solution, or a NAS. Instead, these servers use the local NVME disks for those databases and replicate them by using the application layer. Doing this means each database type has its own replication mechanism. For the most part, this replication is part of the software itself.
The bare metal persistent storage machines are not provisioned by Fleet, as yet. The plan is to eventually have Fleet provision these machines, but Kubernetes will not run on top of these nodes.
Agoda operates and manages all the databases and its DBA team has automated the operations of their data layer, including automated replication functionality. For data persistence, many applications get most of what they need from this DBAAS layer. However, some applications also need blob storage and an S3-like interface. For blob storage, the company uses Ceph for most use cases; a solution which provides object, block, and file storage in a single unified system.
Additionally, in 2022 Agoda purchased VAST Data devices for much better cost-per-byte S3 access. These services are for the big data stack, which stores about 20PB of data.
For big data technologies, Agoda has spent many years on:
HDFS (Hadoop Distributed File System): a distributed file system handling large data sets running on commodity hardware
Spark: a unified analytics engine for large-scale data processing
YARN: resource management and job scheduling for Hadoop
Oozie: a workflow scheduler for Hadoop
Hive Metastore (HMS): a central repository of metadata, and a critical component of many data lake architectures
Impala: the open source, native analytic database for Hadoop
The company is currently transitioning to:
VAST: for universal storage, storing data on top of SSD drives with S3 protocol accessibility
Spark: the only part of its old stack that Agoda keeps for large-scale data processing.
Kubernetes: to automate deployment, basically replacing YARN
Kubeflow: mostly to replace Oozie as a workflow scheduler for Kubernetes
Iceberg: the high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark or Impala to safely work with the same tables, simultaneously. Agoda is replacing HMS with Iceberg.
Agoda might need other technologies as it migrates to the new stack. This is a work in progress and an exciting challenge. For example, the engineering team is looking into Impala replacements, but hasn’t reached a decision yet.
The custom ETL (extract, transform, load) tooling is built on top of Spark. Agoda fitted this tool with a simple user interface. This tool resembles dbt (data build tool) in some ways, but has lots of handy customizations. Before building their own tool, the team looked deeply into dbt. It transforms raw data stored in warehouses into data models that use SQL, a bit of Python or Jinja.
This is how Idan describes why Agoda built a custom ETL pipeline:
‘I think that dbt is great, overall. It has features that already existed in our tool which I really agree with:
The focus on SQL as a language to describe data transformations, versus the previous trend of doing all data transformations with Python
Jinja as a way to extend SQL and make it more “don’t repeat yourself” (DRY.)
However, our workflows were heavily SQL-driven and performed on an isolated Spark application. Our workflows also have steps that are not necessarily pure SQL, such as connecting to an API. We felt that the dbt approach is a bit too puristic. While we were inspired by it, we felt it was easier and better for us to incorporate those ideas in the new generation of our tooling, instead of committing 100% to the dbt approach. An example of an inspiration we took from dbt was to update git first and let the CI/CD pipeline update the real workflow, and to use Jinja as a templating engine.’
Agoda has a custom data science platform with a collection of tools for data scientists and ML engineers, including:
a feature store
a notebook solution
a command line tool to launch and schedule ML applications
a model serving solution. This converts a model to an API and deploys it
a model store, which is where model training results are kept
a data health solution that checks data is correct before feeding it into models
Most of these tools are home grown and built on top of open-source tools.
For data visualization the company uses Metabase, Grafana and Tableau, and runs all solutions on prem.
Other technologies Agoda uses or has built:
Vertica: a big data analysis tool for analyzing a subset of data. The company found that in specific cases, Vertica’s price-for-performance is unbeatable after trialing all major cloud offerings in the big data sector to compare pricing and performance.
Parquet: stores a lot of Agoda’s data in a column-oriented data file format designed for efficient data storage and retrieval.
Kafka: an open-source distributed messaging system for stream processing and real time data pipelines. Agoda currently sends 2 trillion messages per day. The company has written about its use of Kafka. Kafka powers Agoda’s messaging framework that generates half of all data going into its data warehouse. The other half of the data comes from various SQL engines.
Custom framework to convert Kafka streams with known schemas to Parquet files, and do all this efficiently. This custom framework does conversion for about 2,000 Kafka topics.
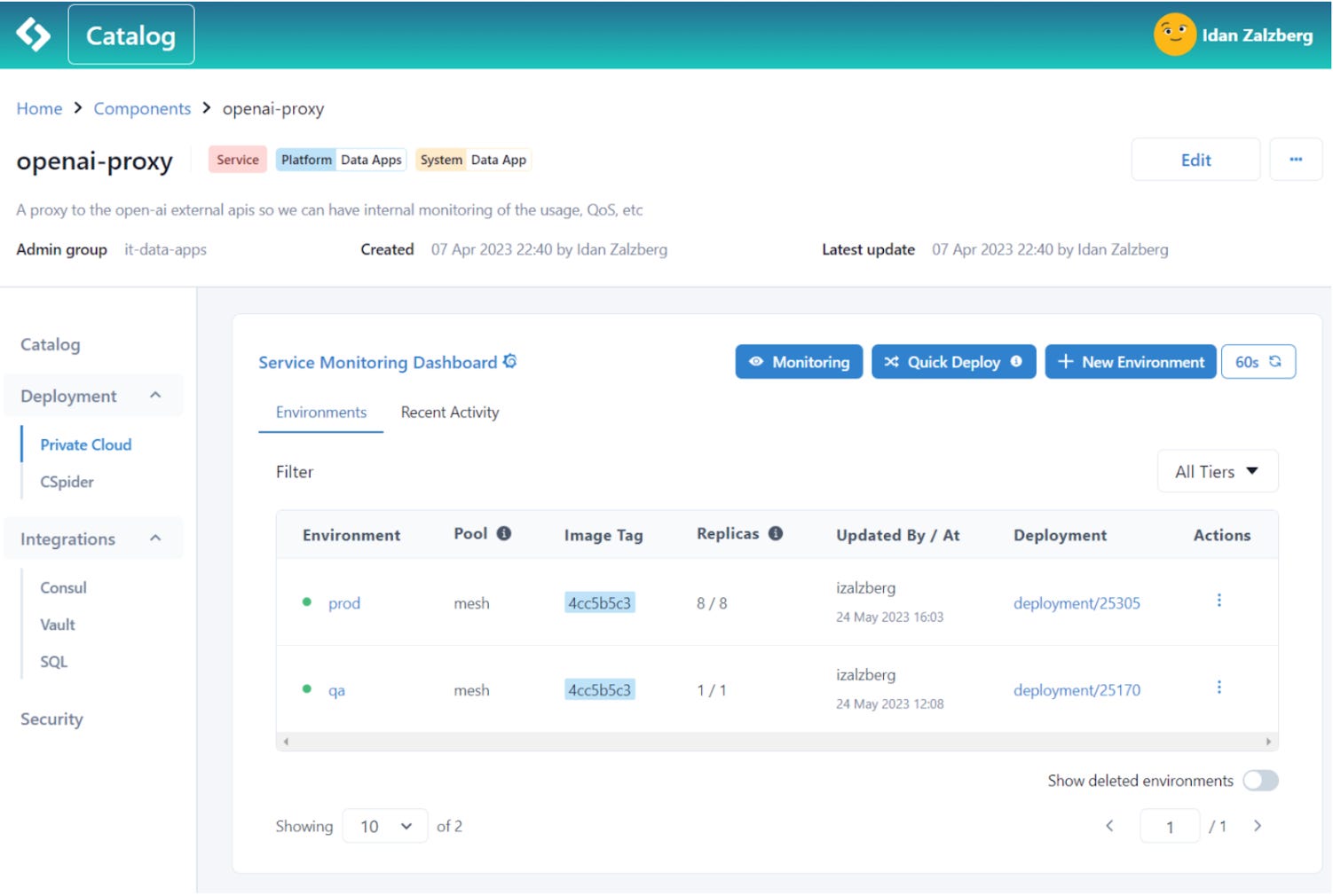
Developer portal
Agoda’s dev-portal is a software catalog with about 2,500 services, of which around 1,500 are currently running in production. The company built its own dev portal from scratch and evaluated Backstage, a popular open-source developer portal. Back then, Backstage was much more of a “read only” kind of interface. Agoda wanted something which also guides developers in creating new services, or with tasks such as integrating Vault (a secrets storage on the HashiStack) into your service. Talking with Idan, he added more context:
‘Backstage has come a long way and at some point, Agoda should probably reconsider whether to onboard to Backstage over maintaining our own developer portal.
I do think that a dev-portal is a very opinionated piece of technology. Most of the work is “integration-like” work anyway, so I don’t think the cost of building our own was that much of an investment. It’s more about getting all of our ecosystem to connect with it, authorization and approval processes, and so on.’
We did a deep dive into Backstage in the issue Backstage: an open-source developer portal.
Here’s what this developer portal looks like:

2. Agoda’s cloud strategy and usage
The remainder of this article is a question-and-answer session between Idan and I. The questions are in italics.
Agoda not moving to the cloud is interesting as it’s a “sibling” of Booking.com, which has started to move to the public cloud. So why has Agoda not done so?