
Building, launching, and scaling ChatGPT Images
ChatGPT Images is OpenAI’s biggest launch yet, with 100 million NEW users generating 700 million images in the first week. But how was it built? A deepdive with OpenAI’s engineering team

ChatGPT is the fastest-growing app of all time: from its launch in November 2022, it took the AI chat assistant only 12 months to hit 100M weekly active users. And new figures show that growth is speeding up. ChatGPT Images released at the end of March, and an incredible 100 million new users signed up in the first week. This load was far higher than OpenAI had expected and prepared for, but the launch passed with no major outages.
Afterwards, I sat down with two engineering leaders deeply involved in ChatGPT Images: Sulman Choudhry (Head of Engineering, ChatGPT) and Srinivas Narayanan (VP of Engineering, OpenAI). In this article, they share previously-unreleased details about the Images project, and behind-the-scenes details of how the team pulled the launch off.
For extra context, check out a previous deepdive with the ChatGPT team, including how OpenAI ships so fast, and the real-world scaling challenges they solved.
Today, we cover:
Launch. Higher-than-expected load from the start, going viral in India, and getting up to 1 million new users per hour signing up.
How ChatGPT Images works. Image tokens, a decoder, multiple passes to generate an image, and also the tech stack: Python, FastAPI, C, and Temporal.
Changing the engine while speeding on the highway. What to do when your system struggles under rising load. The ChatGPT team rewrote image generation on-the-fly from synchronous to asynchronous, with users noticing none of this effort.
Reliability challenges. The load on ChatGPT Images overwhelmed other OpenAI systems, and was higher than the team had expected. Major outages were avoided thanks to months spent isolating systems, doing regular load testing, and ongoing efforts to monitor and alert for reliability.
Extra engineering challenges. Third-party dependencies, an unbelievable “vertical growth spike”, and new users adding unexpected load by hanging around.
From “GPU constrained” to “everything constrained.” A year ago, ChatGPT was heavily GPU constrained. Having solved that bottleneck, the new bottleneck is “everything constrained”.
How does OpenAI keep shipping so rapidly? Infra teams’ #1 focus is on shipping fast, blurred roles across engineers/researchers/PMs/designers, the heavily used DRI role, and more.
As every deepdive, this one also reveals new details about how OpenAI’s engineering team operates and on engineering challenges in building and operating ChatGPT. Other related deepdives from last year:
This article is from the Real-world engineering challenges series. See all others here.
1. Launch
OpenAI keeps launching new features at a rapid pace. In one month, they launched:
5 March: ChatGPT 4.5 – a new model
6 March: ChatGPT for MacOS code editing abilities within IDEs
11 March: Agent Tools for developers
13 March: Python-powered data analysis – allowing things like running regressions on test data
20 March: voice agents with new audio models launched in the API
Then, on Tuesday, 25 March 2025, OpenAI released Image Generation using the 4o model:

It’s hard to predict if a launch will achieve “cut through” by becoming an event in itself. ChatGPT’s head of engineering, Sulman Choudhry, reveals this wasn’t widely expected of ChatGPT Images, internally:
“At the scale that we're at now with ChatGPT, we thought we were as ready as can be for any launch. After all, we've done dozens of launches – including some very massive ones – in the past several months. However, the Images launch turned out to be orders of magnitude larger than anything we've seen so far.
It was also the first massive launch that happened after we’d scaled out already. It’s of an unexpected scale which I was surprised we had to deal with.”
Sulman calls the launch the craziest of his entire career – and this from someone who scaled Facebook Video to 5 billion daily views back in 2014. The team designed ChatGPT Images expecting to drive meaningful growth similar to the DALL-E 3 images feature launched in October 2023. But they simply did not expect as much growth as what happened.
The plan was to initially release ChatGPT Images to paying subscribers, and then free users later on the same day. However, as things unfolded it was decided to postpone launching to free users:

But the OpenAI team wanted to get Images in front of free users, so despite the high ongoing load, a day later (on 27 March) they started a gradual rollout to free users. At this point, traffic ratched up, big time.
Viral in India
As soon as free users got access to ChatGPT Images, usage in India blew up: celebrities in the country shared images created by ChatGPT in the Ghibli animation style, such as India’s most famous cricketer, Sachin Tendulkar:

The Prime Minister of India, Narendra Modi, was depicted in images recreated in Ghibli style:

Srinivas told me:
“This launch quickly became really special for me: my entire family was in India and they also started sharing old pictures recreated with ChatGPT, just like the rest of the country. The feature really hit big in India.”
Ghibli-style generation has remained one of the most common use cases – and one I’ve played around with by turning existing photos into cheerful, anime-style images.
Launch stats
The team worked around the clock to ensure paying users could keep generating images, and preparing for the launch to free users. Five days after everyone got access, the load was still high enough that additional work was needed to keep things up and running:

On day six, 31 March, yet another viral spike added one million users in just one hour:

Launch stats:
100 million: new users signing up in the first week of the feature’s release
700 million: images generated in the first week
1 million: new users signing up during a one-hour period on day six of the launch
Despite unexpectedly high traffic, ChatGPT avoided hard outages like the site going down, and maintained availability for existing users. At peak load, latency did regress, but the team prioritized keeping the service accessible. They kept the site responsive by applying rate limits and increasing compute allocations to stabilize performance. Shortly after the peak, they returned to normal rate limits and brought latency back to acceptable levels.
A rule of thumb the ChatGPT engineering team uses is to intentionally prioritize access over latency. So, at times of unexpected growth, latency is often the first tradeoff made to keep the platform up.
2. How ChatGPT Images works
Here’s how image generation works, as described by Sulman:
You ask ChatGPT to draw something, and then:
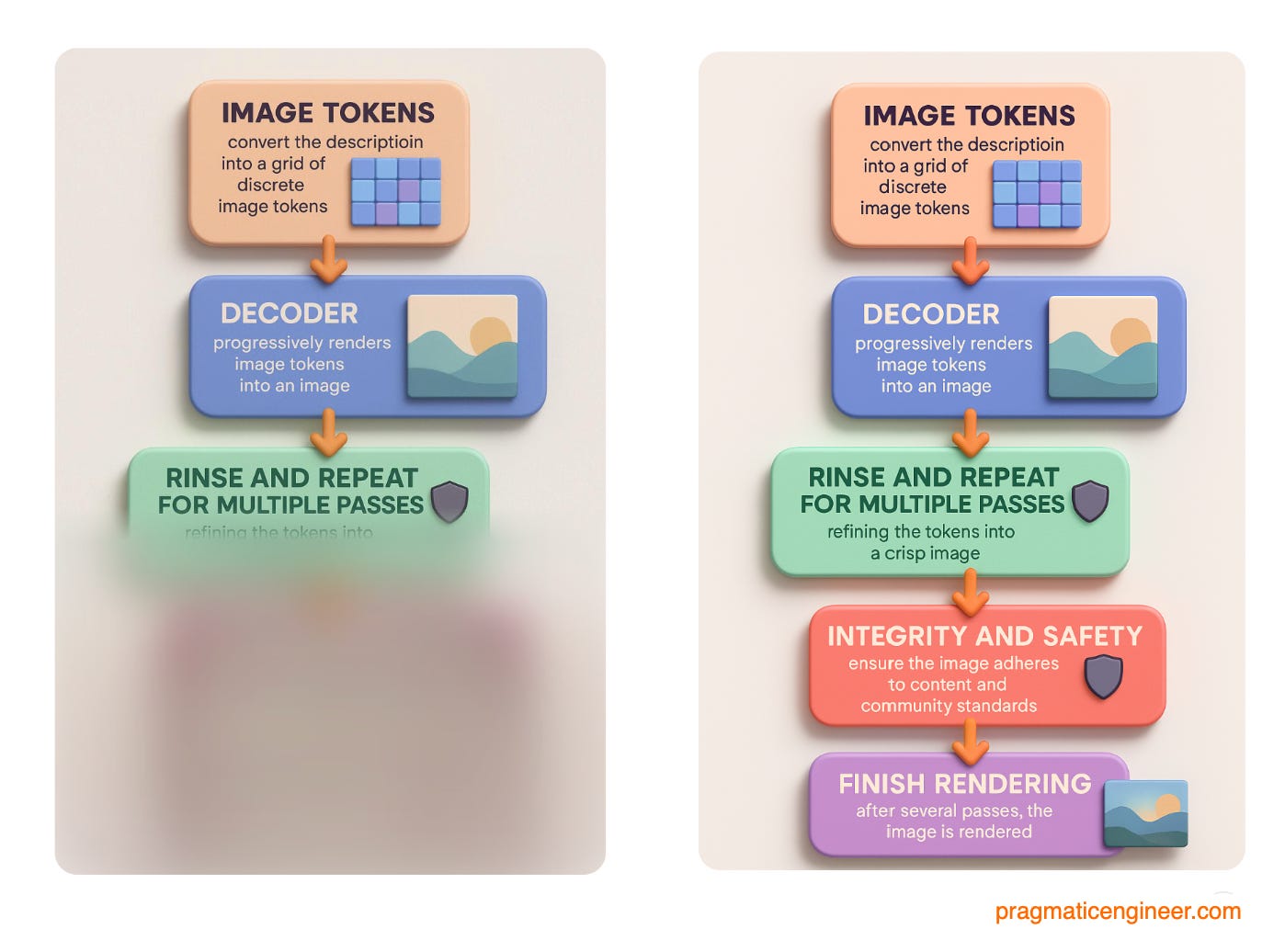
Image tokens convert the description into a grid of discrete image tokens. These tokens natively encode image content.
Decoder progressively renders image tokens into an image.
Rinse and repeat for multiple passes: when you generate an image, it is very blurry to start with and then gradually becomes clearer. This is the decoder refining the tokens into a crisp image through multiple passes.
Integrity and safety: throughout rendering, there are processes to ensure the image adheres to content and community standards. If not, rendering is aborted.
Finishing rendering: after several passes, the image starts to crispen up, and then is rendered to the user.
Here’s an image generated by these steps:
Another feature of ChatGPT images is that you can iterate on a generated image with new prompts. This operation takes the existing image (with tokens) and applies a new prompt on top, meaning it’s possible to tweak an image:

“Tweaking” an existing image is a practical feature, but it involves a lot more resource usage because the same compute operations execute each time a “tweaked” image is generated.
Tech stack
The technology choices behind the product are surprisingly simple; dare I say, pragmatic!
Python: most of the product’s code is written in this language.
FastAPI: the Python framework used for building APIs quickly, using standard Python type hints. As the name suggests, FastAPI’s strength is that it takes less effort to create functional, production-ready APIs to be consumed by other services.
C: for parts of the code that need to be highly optimized, the team uses the lower-level C programming language
Temporal: used for asynchronous workflows and operations inside OpenAI. Temporal is a neat workflow solution that makes multi-step workflows reliable even when individual steps crash, without much effort by developers. It’s particularly useful for longer-running workflows like image generation at scale
3. Changing the engine while speeding on the highway
The ChatGPT team designed Images to be a synchronous product: when an image starts rendering, it needs to finish in a synchronous way. If the process is interrupted, there is no way to restart it, and while an image is rendering, it continues using GPU and memory resources.
The problem with this setup is that it can’t handle peak load by taking advantage of excess capacity at non-peak times. Sulman recounts how the team decided to rewrite image generation engine, while dealing with rapidly-rising load:
“It was the first or second night after Images launch, and demand was bigger than we’d expected. The team got together and we decided that to keep the product available and keep the service up and running for all users, we needed to have something asynchronous – and fast!
Over a few days and nights, we built an entirely asynchronous Images product. It was a bunch of engineers rolling their sleeves up – and we kicked off a parallel workstream to get this new implementation ready. All the while, a bunch of us worked on keeping the site up and running under the intense load.
Once the asynchronous product was ready, we were able to “defer” the load on our systems: for free users, we would route that traffic to an asynchronous system when load was too high. These requests would get queued up and once our system had extra cycles to spare, we got to generating those images.
This meant that we traded off latency (time to generate free images) for availability (being able to generate images)”.
Isolating other OpenAI systems
A viral launch is usually great news, except when it takes down other parts of the system! In the case of ChatGPT, the product is used by paying users (many of whom are developers), as well as larger enterprises on enterprise plans. Ideally, ChatGPT Images’ unprecedented load should not impact other systems. But due to the increased load, several underlying infrastructure systems were impacted:
File systems storing storing images hit rate limits
Databases: OpenAI’s database infrastructure got overloaded because the rapid growth was unexpected.
Authentication and onboarding: the authentication and new user signup systems got so much load that they came close to tipping over
OpenAI has always had strict reliability standards for the OpenAI API, and many systems were isolated from ChatGPT traffic.
However, there were still some shared components for which there was a plan to isolate, which hadn’t happened yet; such as a couple of compute clusters, and a shared database instance. Seeing the sudden surge and impact on otherwise independent systems made the team speed up their isolation work. They decoupled non-ChatGPT systems from the ChatGPT infrastructure, and most OpenAI API endpoints stayed stable during the Images-related spike, thanks to prior work on isolation. They also wrapped up the work of isolating non-ChatGPT endpoints from ChatGPT infra.
Improving performance while finding new capacity
Images encountered a compute bottleneck, so the team started to push changes that improved performance and they sought quick performance wins, even before capacity was increased. Srinivas (head of engineering, OpenAI) recalls:
“When you're moving quickly, you can easily have too much tech debt accumulated, including code that is not particularly optimized. One of our bottlenecks was our database, so our team started to look for database queries that were taking too many resources. Looking closer, it was clear that some of these were doing unnecessary things.
So, on the spot, we had a spontaneous workstream form of people working through the night to figure out how to make our existing code more efficient. We made changes to existing systems to use fewer resources. At the same time, we had other teams working hard to bring up new capacity across systems like filesystems and databases.”
4. Reliability challenge
ChatGPT working reliably with higher-than-expected load was key to the successful launch. Here’s how the team prioritized this non-functional requirement.