


Real-World Engineering Challenges #1
Caching, multi-tenancy, E2E tests, and database cutovers.

👋 This is Gergely with a bonus issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at big tech and high-growth startups through the lens of engineering managers and senior engineers.
If you’re not a subscriber yet, here’s what you missed the past weeks:
Hiring an engineering manager: a framework you can follow, and, and an overview of how Facebook, Amazon and Stripe do it
Preparing for promotions ahead of time both as someone wanting to get promoted, and as an engineering manager
The perfect storm causing an insane tech hiring market and advice on how to stay ahead
Follow-up on the insane tech hiring market with more data and comments
Subscribe to get this newsletter every week 👇
Real-World Engineering Challenges is a bonus column I’m starting as additional content on top of the weekly articles. Here, I share a handful of the most interesting real-world engineering challenges I came across this month, based on engineering blog posts from tech companies. This is the first issue - and an experiment of this format.
I pick pieces that cover interesting engineering approaches, and you can learn something new by reading them, and diving deeper into the concepts they mention. Read something that fits this? Share it with me!
Shopify made their app 20% faster by… caching on the backend
Shopify built their app on top of React Native and noticed how the home page was starting to become slow on loading. This was because the Rails backend made multiple database queries, adding latency. The solution to this problem was - surprise! - adding a cache in front of those queries.
The article goes into design considerations on choosing between Memchached and Redis, and touches on concepts like write-through caching, cache invalidation and the tradeoffs of delete-then-write strategies.
What I really liked about this writeup is how they talk about one of the most challenging parts of a project impacting millions of customers: rolling out caching changes. They detail how they ran an experiment and how they fixed issues that the experiment surfaced before rolling out fully.
Doordash introduced multi-tenancy for their user data
Doordash ran into an interesting use case where they wanted to create duplicate users so different user instances could be used for each of their Storefront merchants. They decided to use a multi-tenancy approach.
In practice, this meant adding a tenant_id column to all user-related tables. They then made code changes, so all related systems started to use this tenant_id, and all systems routed this information, including passing through headers. Once this was all done (complex work in itself!), they added enforcing rules to the database.
Multi-tenancy is a sensible approach as companies grow and scale and an approach worth becoming familiar with. Uber, for example, uses a similar multi-tenancy approach in their microservices architecture.
Airbnb improved developer productivity for their 70+ iOS engineers
The Airbnb iOS app has 1.5M lines of code, 75 engineers working on it, and is localized in 62 languages. This puts them as one of the larger mobile app teams.
With this growth, came frustrations like Xcode now taking minutes to load the project, long build times and slower overall iteration for engineers. These are all common to pain points I’ve experienced at Uber as the codebase and team grew and are a few of the many challenges of scaling up mobile engineering - the exact topic I wrote my book Building Mobile Apps at Scale about.
Airbnb has an iOS infrastructure team in place who take ownership of improving mobile developer efficiency and experience. This is similar to how other, similarly sized mobile organizations approach engineering productivity. The mobile developer platform was one of the first platform teams Uber funded after they introduced platform teams. Here’s what Airbnb’s iOS infra team did to reduce frustrations and improve mobile productivity:
Introduce a better build system. They went with Buck.
Introduce code hierarchy to improve discoverability by introducing a semantical grouping they call module types.
Create lightweight Dev Apps (a term Airbnb introduced) that is an on-demand Xcode workspace for a single module and dependencies.
I especially like the concept of Dev Apps: almost every team struggling with slow build times created these “skeleton apps” manually for themselves, but it’s the first time I heard the infra team building tooling to generate these.
Engineering being productive when building large mobile apps keeps being a hard problem, and there are few easy solutions.
GitHub reduced their MySQL database load by partitioning it
GitHub started out as a Ruby on Rails app with a MySQL database and MySQL remains at its core. In 2019, they decided to partition the database to reduce both load, and database-related incidents. The article is a detailed walkthrough of the staggering amount of work they had to do to enable partitioning:
Concepts: virtual partitions, schema domains
Tooling: SQL linters to enforce virtual boundaries: query linter, transaction linters and how polymorphic tables pose another set of problems. Vitess as a tool to move tables with no downtime.
Moving data with no downtime: using a write-cutover process to move database connections between clusters without losing data.
A term I came across for the first time - and could not find a definition to link to - is database cutover. This means rapidly transitioning from one database to the other, as part of the migration. The shorter the downtime, the better, and GitHub pulled off a zero-downtime cutover approach.
The article is dense and well-written. I found it a good reminder on how if you find your framework or service not supporting a use case - like partitioning - you can build this by using a mix of existing, industry-standard tools, and building your own tooling. And how migrating databases with no downtime, though challenging, should be the standard to aim for: if GitHub could do it with such high load, so can anyone else.
Nubank killed their end-to-end test suite
Brazil-based neobank Nubank had previously put E2E tests in place, but soon realized the many downsides. Slow test suites, flakey tests, and expensive maintenance and four more reasons.
So how did they convince engineering leadership to make a major change? They pulled the ultimate card of demonstrating how the build will take close to infinite time to build, using queuing theory:
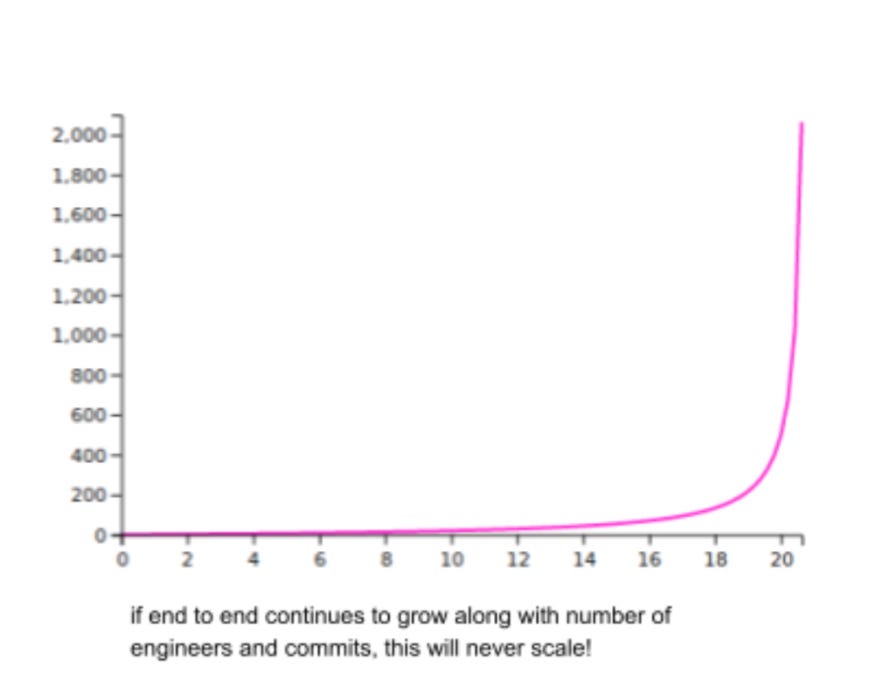
Nubank is now experimenting with consumer driven contract testing, created a framework around this and discuss more details in the article.
My take is that end-to-end tests are hard to do right, mostly due to the tooling just not being there. Nubank being open about how it just didn't work for them is a refreshingly honest admission.
However, I do not fully buy the takeaway of how end-to-end tests are just not practical enough. I’m surprised they did not look deeper into why those tests were flakey. I also think that black box tests to exercise key parts of the system - which are typically a variation of E2E ones - have lots of added value. A good use case if having a black box testing suite to quickly validate if your key systems are up or down. For example, Uber utilizes these kinds of black box tests as part of their alerting system.
Awaiting the Shopify engineering blog where the cache causes a major outage, because that's what Redis and Memcached nearly always do when they're used to paper over a design that doesn't scale.